
Exprimiendo la función JERARQUIA de Google Sheets

En este artículo diseñaremos paso a paso una función con nombre para las hojas de cálculo de Google capaz de analizar un listado de valoraciones y devolver el subconjunto de los participantes mejor clasificados en uno o más conjuntos de comparación.
TABLA DE CONTENIDOS
Hola, problema, te presento a unos amigos
La verdad es que no sé si empezamos demasiado bien 😅. No estoy nada seguro de que el resumen inicial con el que pretendía seducirte para que me acompañaras en esta nueva aventura hojacalcúlica te haya dejado claro cuál será nuestro objetivo hoy.
Posiblemente no. ¡Gemini, échame un cable!
🤖
¡Vamos a crear juntos una función súper útil para Google Sheets! Esta herramienta analizará tus listas de puntuaciones y te mostrará automáticamente quiénes son los N primeros en cada grupo que definas.
¿Mejor? 🤔
La necesidad de disponer de una herramienta para obtener, rápidamente y sin errores, la relación de entidades mejor clasificadas a partir del análisis de una tabla de valoraciones con puntuaciones numéricas surgió hace unas semanas, como tantas otras veces, en el ámbito de algo que hacemos en el centro en el que trabajo.
Además de ciclos formativos de FP, también desarrollamos una programación anual de cursos subvencionados por LABORA destinados a mejorar la empleabilidad de personas desempleadas. Entidades como la nuestra participan en un procedimiento de concurrencia competitiva para obtener fondos que permitan promover, de manera gratuita para las personas participantes, una serie de acciones formativas de distintas especialidades propuestas anualmente por LABORA.
Estas subvenciones, que se conceden de manera específica e independiente para la ejecución de cada acción formativa, son asignadas a aquellas entidades que obtienen las puntuaciones más altas en un proceso de baremación en el que se contemplan una serie de criterios técnicos. Las puntuaciones obtenidas en estos criterios —11 en la convocatoria de 2024— se totalizan para obtener una puntuación total (PT) en cada una de las acciones solicitadas por cada entidad, puntuación que determinará en última instancia cuál será la ganadora que la ejecutará.
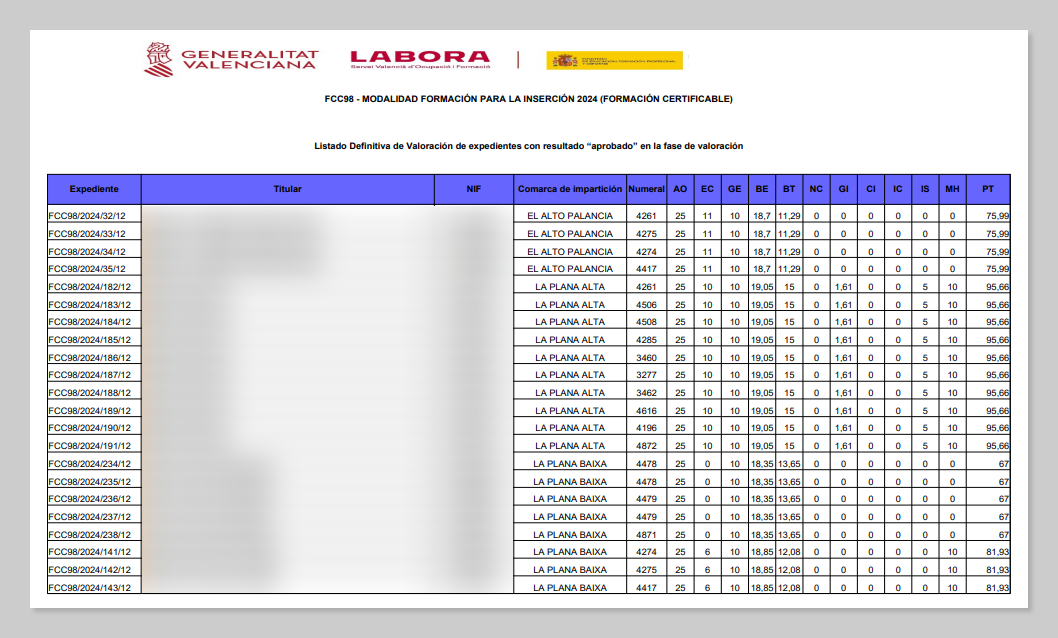
LABORA normalmente publica los listados que recogen estas valoraciones unos meses antes de enviar las resoluciones de adjudicación a las entidades beneficiarias. De este modo, las entidades que han participado en el proceso puedan verificar si hay algún error y, en su caso, solicitar su subsanación.
Como te puedes imaginar, es conveniente disponer cuanto antes de esta información. Y no solo para corregir posibles errores, sino también para poder establecer la planificación de los cursos asignados con la mayor antelación posible.
Nuestro objetivo será hoy por tanto diseñar un mecanismo que permita masticar toda esa información tabular, una ensalada de números de expedientes (cursos), entidades solicitantes y puntuaciones obtenidas, ordenada de un modo que no resulta particularmente útil, y que se extiende a lo largo de un número más que respetable de páginas.
🎯 De manera más específica, lo que pretendemos es obtener con facilidad un listado de las acciones formativas en las que nuestra entidad ha obtenido la valoración ganadora, o en su defecto una comprendida entre las dos o tres más altas, puesto que es frecuente que se produzcan reasignaciones tras el envío de las resoluciones administrativas por renuncia de los primeros adjudicatarios.
Como los detalles específicos de este procedimiento administrativo de LABORA no son relevantes en el proceso de diseño de una función con nombre que resuelva el problema me he tomado la libertad de preparar un conjunto de datos simplificado y así abstraer el problema:
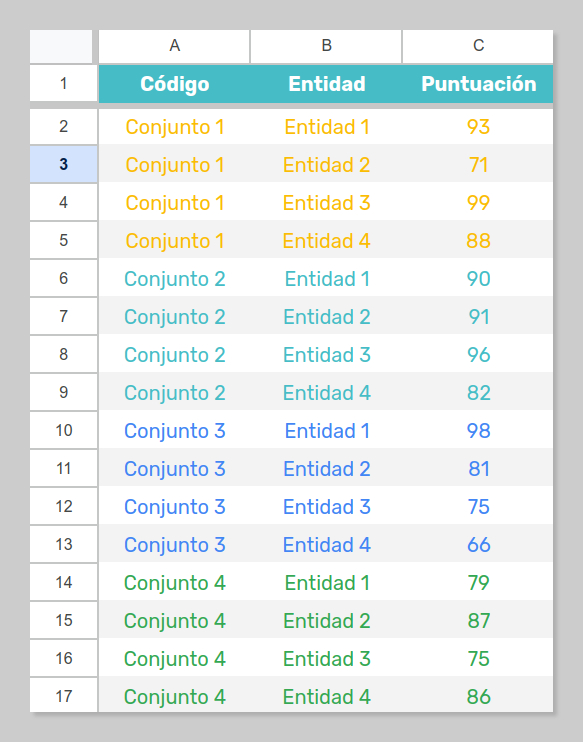
Utilizaremos la columna Código para caracterizar los distintos conjuntos de valoraciones (equivalente al Expediente de la acción formativa por el que compiten las entidades en el listado de valoraciones de LABORA). Las columnas Entidad y Puntuación creoque no merecen mayor comentario.
En este tabla de ejemplo podemos apreciar que cuatro entidades distintas han sido valoradas cuantitativamente en el contexto de cuatro procedimientos competitivos análogos. He ordenado la tabla por código y entidad, pero naturalmente las filas podrían presentarse ordenadas de un modo diferente, incluso completamente aleatorio.
Los requerimientos de diseño son estos:
- Partiremos de un intervalo de datos que contiene en sus filas una serie de valoraciones caracterizadas por las columnas que identifican el conjunto de valoraciones, el participante y la propia valoración cuantitativa o puntuación obtenida.
- Deseamos obtener como resultado un conjunto de datos de salida que contendrá las filas del intervalo de entrada que cumplan las siguientes condiciones:
- La puntuación obtenida se encuentra dentro de las N mejores de la clasificación.
- El participante forma parte de un subconjunto de los participantes que aparecen en el intervalo de datos.
- El mecanismo debe admitir las siguientes parametrizaciones:
- Las columnas conjunto, participante y valoración se indicarán mediante números enteros positivos que representan su posición desde el extremo izquierdo del intervalo de datos de entrada.
- El valor umbral utilizado para seleccionar las filas correspondientes a los N participantes mejor clasificados dentro de cada conjunto de valoraciones. Si se producen empates, se devolverán todas ellas.
- La lista de participantes cuyas valoraciones deben devolverse, es decir aquellos en los que estamos únicamente interesados.
- El criterio utilizado para determinar si la puntuación asignada a los participantes es mejor o peor, que podrá ser de tipo ascendente (menor es mejor) o descendente (mayor es mejor).
- Adicionalmente, será posible incluir en el resultado la fila de encabezados del intervalo de datos de entrada, si es que este dispone de ella.
- Al igual que en este ejercicio de diseño previo, y por razones análogas, la implementación se hará utilizando una práctica y conveniente función con nombre.
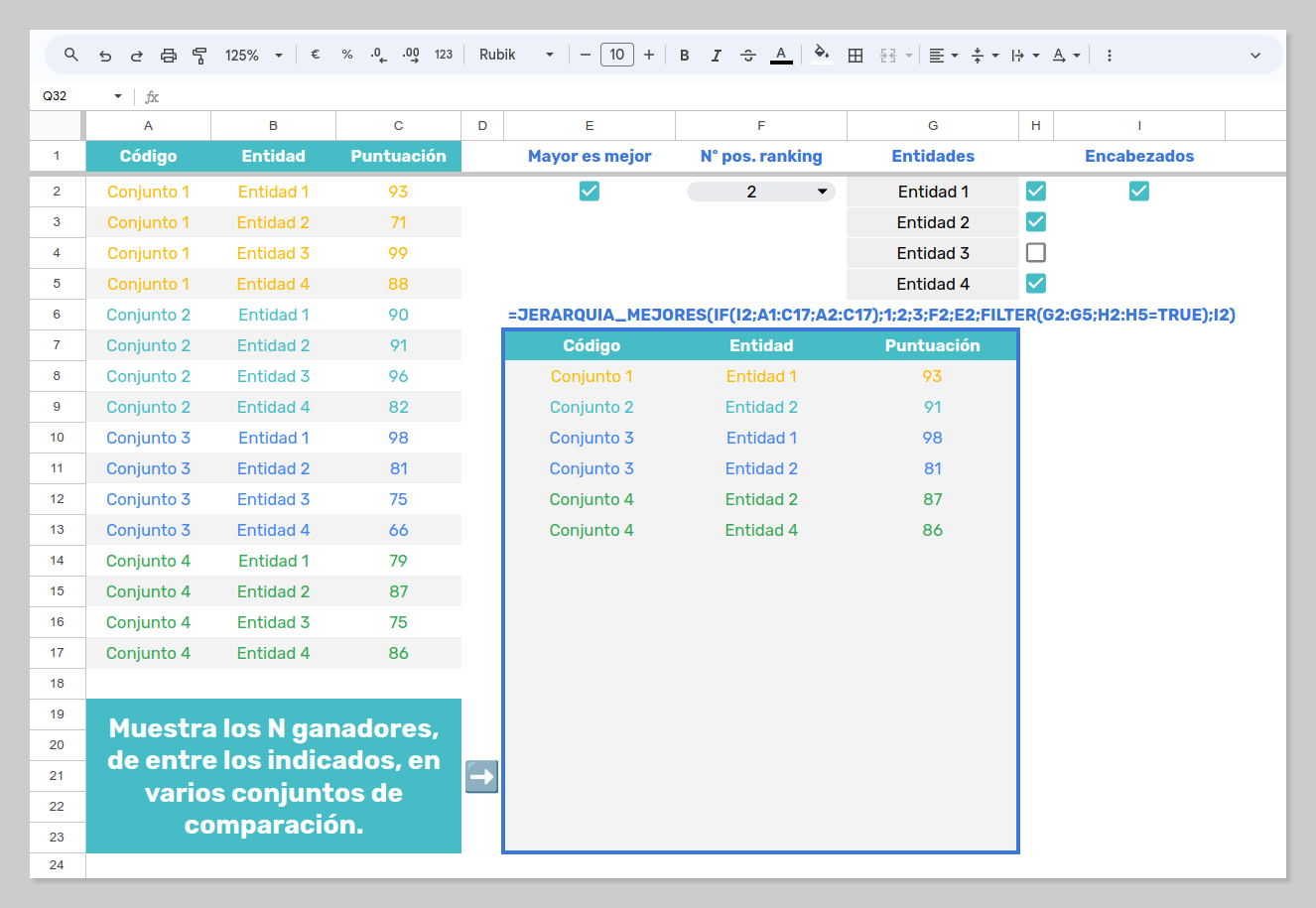
Pero nada mejor que contemplar una versión casi final de nuestra criatura en acción, aunque añadiremos alguna funcionalidad adicional a lo largo del artículo:

Las funciones integradas JERARQUIA y K.ESIMO.MAYOR/MENOR
Lo primero en lo que pensé tras definir el problema fueron estas tres funciones nativas de Google Sheets:
| JERARQUIA | K.ESIMO.MAYOR | K.ESIMO.MENOR |
| Ofrece la clasificación de un valor determinado de un conjunto de datos de modo ascendente o descendente. | Ofrece el enésimo elemento mayor de un conjunto de datos, donde el usuario define el valor de n. | Ofrece el enésimo elemento menor de un conjunto de datos, donde el usuario define el valor de n. |
El funcionamiento de todas ellas es de lo más inmediato. Veamos algunos ejemplos:
| JERARQUIA(valor; datos; [es_ascendente]) (si es_ascendente es 0 o no se indica se asume que el valor mayor tiene rango 1) | |
JERARQUIA( | JERARQUIA( |
| K.ESIMO.MAYOR(datos; n) | K.ESIMO.MENOR(datos; n) |
=K.ESIMO.MAYOR( | =K.ESIMO.MENOR( |
Está claro cómo funcionan, ¿verdad?
La función JERARQUIA nos permite obtener de un modo sencillo la clasificación de un valor dentro de un conjunto, atendiendo a un criterio de determinación del rango descendente (por defecto) o ascendente. No obstante, podríamos lograr un resultado similar con esta expresión:
COINCIDIR(valor; SORT(WRAPROWS(datos; 1); 1; es_ascendente); 0)
Las funciones K.ESIMO, por su parte, lo que hacen realmente es devolver el valor situado en una posición arbitraria de un conjunto de datos numéricos atendiendo a un criterio de ordenación ascendente (K.ESIMO.MENOR) o descendente (K.ESIMO.MAYOR). Por tanto, también podrían sustituirse por algo así:
INDICE(SORT(WRAPROWS(datos; 1); 1; es_k_esimo_menor); n)
☝ Dado que que SORT solo trabaja por columnas, estas versiones alternativas que te propongo de las funciones JERARQUIA y K.ESIMO precisan de la función WRAPROWS para asegurarse de que el intervalo de datos sea un vector columna.
Bien, ya hemos diseccionado (solo lo justo y necesario) estas tres interesantes funciones. Cierto es que suponen poco más que envoltorios para expresiones no demasiado complejas (reconstruir los mecanismos internos de una función suele ayudar a la hora de entender completamente cómo operan), pero estarás de acuerdo conmigo en que aportan un mayor nivel de abstracción que sin duda hará que tus fórmulas sean más fáciles de entender.
Lo que resulta evidente es que solo con ellas no vamos a ser capaces de satisfacer los requerimientos establecidos para la solución que pretendemos diseñar.
Construyendo la función con nombre JERARQUIA.MEJORES
Cuando se trata de procesar información, una de las funciones más potentes con las que contamos en el lenguaje de fórmulas de las hojas de cálculo de Google es QUERY. Pero eso ya lo sabías, ¿verdad?
Esta función constituye una auténtica navaja suiza que esconde algunas capacidades ciertamente insospechadas. QUERY cuenta con un potente lenguaje de consulta que no se limita a al uso de criterios muy granulares para filtrar un conjunto de datos tabulares, sino que también permite agregarlos (agregar es algo así como reducir y resumir) e incluso realizar operaciones al vuelo sobre ellos.
Tanto si no conoces QUERY como si ya la utilizas habitualmente, te recomiendo que le des una leída a este excelente artículo para asegurarte de conocer (casi 😏) todas las posibilidades que ofrece.
Con un sencillo QUERY resulta inmediato:
- Obtener las filas de un tabla que contengan la valoraciones de un conjunto específico de valoraciónes.
- Ordenar las filas por la puntuación de cada una de ellas.
- Limitar el número de resultados obtenido.
Por ejemplo, identifiquemos las filas de esta tabla que contienen las dos puntuaciones más altas del primer conjunto de comparación, en orden decreciente:
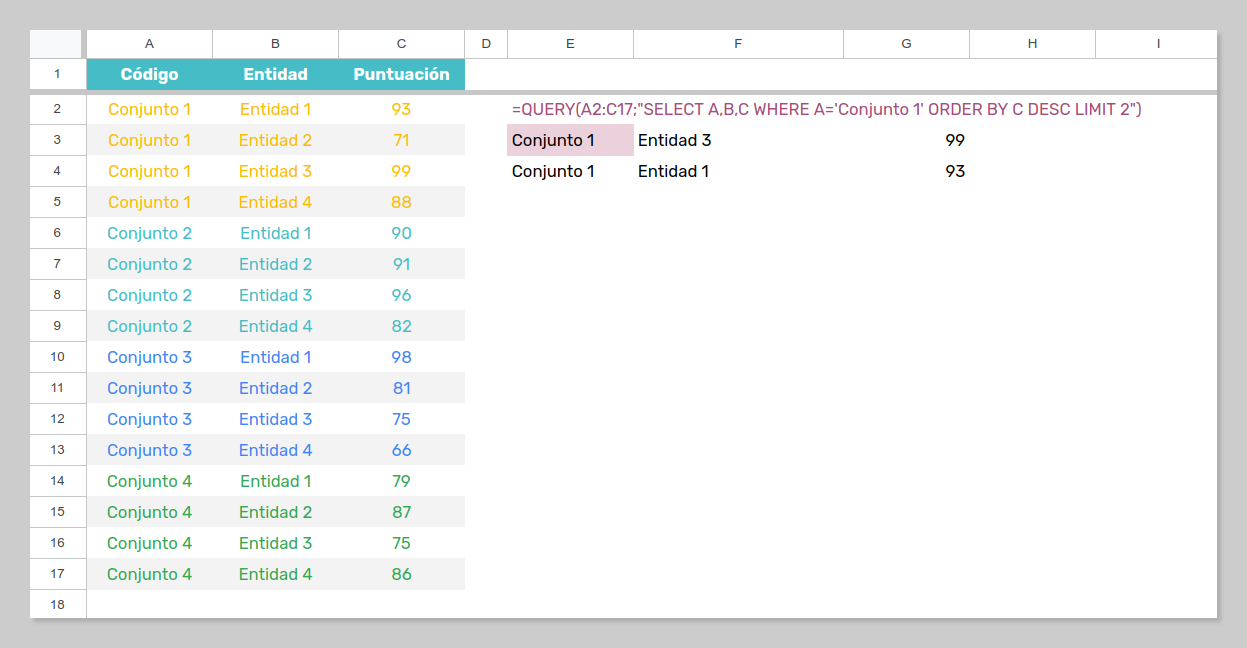
=QUERY(A2:C17;"SELECT A,B,C WHERE A='Conjunto 1' ORDER BY C DESC LIMIT 2")
Esto no está nada mal, cierto.
No obstante, de acuerdo con nuestras propias especificaciones de diseño, no solo deseamos obtener los mejores clasificados pertenecientes a un conjunto de comparación específico, sino los de todos ellos. Y además de manera limitada a ciertos participantes.
☝ Por si fuera poco, obtener los N participantes con mejor puntuación puede no ofrecer exactamente el mismo resultado que hacer lo propio con los que se encuentran en las primeras N posiciones de la clasificación. ¡Atentos a los empates!
Pero resulta que QUERY no se lleva nada bien con ARRAYFORMULA. Y si pretendes utilizar en su lugar BYROW, comprobarás que esta no es ¿aún? capaz de devolver matrices anidadas, tal y como te explicaba al introducir la función MAKEARRAY en el artículo previo de esta serie veraniega sobre Google Sheets.
📝 Análisis comparativo de 3+1 estrategias para obtener submatrices de datos en Google Sheets
Renunciamos pues a la por otra parte fantástica función QUERY. Es un buen momento para que desmenucemos los bloques internos de la función personalizada que estamos tratando de construir, permíteme que la denomine ya abiertamente JERARQUIA.MEJORES, y bosquejar así los elementos clave de la implementación que nos ayudarán a resolver nuestro problema particular.
A vista de pájaro:
| Bloque | Tarea | Funciones clave |
| 1 |
| LET |
| 2 |
| REDUCE |
| 3 |
| LET |
También nos veremos obligados a tirar de un par de ideas felices que tal vez no sean demasiado obvias. Pero todo a su debido tiempo.
La sintaxis de nuestra función JERARQUIA_MEJORES será esta:
JERARQUIA_MEJORES(
tabla_resultados; columna_conjunto; columna_participante;
columna_valoracion; umbral_clasificacion; [mayor_es_mejor];
[lista_participantes]; [encabezados])
Los argumentos entre corchetes pueden omitirse introduciendo un punto y coma [;].
| Argumento | Descripción | Valor si se omite |
| tabla_resultados | Intervalo de datos con las información de conjuntos, participantes y valoraciones. | - |
| columna_conjunto | Índice de la columna que contiene el identificador de cada conjunto de valoraciones (primera por la izq. es 1). | - |
| columna_participante | Índice de la columna que contiene el identificador de cada participante (primera por la izq. es 1). | - |
| columna_valoracion | Índice de la columna que contiene la puntuación de cada participante (primera por la izq. es 1). | - |
| umbral_clasificacion | Establece el número de posiciones en la clasificación que se tendrán en cuenta en los resultados (1 = primera, 2 = primera y segunda, etc.). | - |
| [mayor_es_mejor] | Si es VERDADERO, se devolverá una tabla ordenada por valoraciones en sentido descendente, en caso contrario en sentido ascendente. | VERDADERO |
| [lista_participantes] | Lista de participantes a tener únicamente en cuenta. | Todos los participantes que aparecen en la tabla |
| [encabezados] | Si es VERDADERO indica que el intervalo de datos tiene una fila con etiquetas de encabezado, que se mostrará en el resultado ofrecido por la función. | FALSO |
Un ejemplo de uso (fíjate en cómo se están omitiendo los tres últimos parámetros):
=JERARQUIA_MEJORES(A2:C17;1;2;3;2;;;)
Destripemos a continuación cada uno de los bloques funcionales de JERARQUIA_MEJORES con más detenimiento. Lo haremos yendo de lo general a lo particular, como pelando una cebolla capa a capa hasta llegar a su corazón 🔪🧅 ( no llores).
Bloque 1 | Variables temporales, encabezado y argumentos opcionales
Toda la expresión está envuelta en un LET. De este modo podemos definir una serie de variables que usaremos posteriormente.
=LET(
mayor_es_mejor;SI(ESLOGICO(mayor_es_mejor);mayor_es_mejor;VERDADERO);
encabezados;SI(ESLOGICO(encabezados);encabezados;FALSO);
fila_etiquetas;SI(
encabezados;
CHOOSEROWS(tabla_resultados;1);
"");
filas_resultados;SI(
encabezados;
CHOOSEROWS(
tabla_resultados;
SEQUENCE(FILAS(tabla_resultados)-1;1;2;1));
tabla_resultados);
lista_participantes;SI.ERROR(SI(
ESBLANCO(lista_participantes);
UNIQUE(CHOOSECOLS(filas_resultados;columna_participante));
lista_participantes);lista_participantes);
// [BLOQUES 2 y 3] Generación de la matriz resultado
REDUCE(
...
)
)
☝ Recuerda que no siempre vamos a querer usar LET para reutilizar una expresión y evitar que se calcule más de una vez por una cuestión de optimización, sino también por el simple hecho de mejorar la legibilidad del código de una fórmula.
La definición de las variables mayor_es_mejor, encabezados y lista_participantes realmente constituye una pequeña treta para lograr algo que se aproxima a los argumentos opcionales en las funciones con nombre, una característica que por ahora no soportan de manera nativa.
Esto permite que la función pueda ser invocada omitiendo cualquiera de estos argumentos, aunque para ello hay que introducir un punto y coma [;], incluso cuando se trata del argumento final antes del paréntesis de cierre. Encontrarás una explicación más detallada de cómo funciona este tinglado en el primer artículo sobre funciones con nombre que publiqué en este espacio.
⚠️ Date cuenta de que estoy abusando en cierta medida de LET para sobreescribir los valores de estos tres argumentos de la función con nombre, dado que estoy declarando variables con identificadores idénticos. No lo hago por maldad, sino por comodidad.
Sin embargo, esto que por ahora funciona fenomenal podría dejar de hacerlo en algún momento si el motor del lenguaje de fórmulas de Google Sheets se pusiera más quisquilloso en el futuro. Si tu función comienza a fallar de manera inesperada, tal vez este abuso tenga la culpa. La solución obvia es declarar nombres ligeramente distintos a los utilizados como argumentos, por supuesto.
El caso es que tirando de esta argucia conseguimos que cuando se omitan los argumentos mayor_es_mejor, encabezados y lista_participantes la función con nombre asuma que:
- La clasificación se establezca por puntuación descendente.
- No se utilicen encabezados.
- Se tengan en cuenta todos los participantes.
Para lograr todas estas cosas tan convenientes se utilizan funciones de comprobación del tipo de datos, como ESLOGICO o ESBLANCO, además de otras complementarias, como CHOOSECOLS y UNIQUE, con las que nos encontraremos de nuevo en un momento en un contexto más significativo.
☝ El SI.ERROR en la expresión que trata el argumento lista_participantes es necesario para cazar el error que se producirá al evaluar la función ES.BLANCO cuando lista_participantes es una matriz con múltiples elementos.
Por su parte, la variable fila_etiquetas contendrá la fila de encabezados, si es que el argumento encabezados de la función con nombre es VERDADERO, o bien una cadena vacía [""], en caso contrario. Para establecer esta asignación se emplea la función CHOOSEROWS, que extrae la fila superior (1) del conjunto de datos de entrada.
Por su parte, la variable filas_resultados recogerá las filas de la tabla que contienen los resultados del proceso de valoración, sin la de encabezados, si es que la hubiera. En el caso de que exista una fila de encabezados se extraerán las filas por debajo utilizando nuevamente CHOOSEROWS.
☝ Como te contaba en esta sección del artículo mencionado anteriormente, las funciones CHOOSEROWS y CHOOSECOLS también admiten —oh bendita sorpresa— expresiones matriciales en la lista de argumentos utilizada para indicar los índices de las filas y columnas a extraer. Por esa razón, podemos aprovecharnos de las funciones SEQUENCE y FILAS para construir una lista que enumere todas las filas del intervalo del conjunto de datos de entrada desde la segunda hasta la última.
¿Todos bien? ¡Seguimos!
Bloque 2 | Conjuntos de valoraciones
Vamos ahora con el segundo bloque, que se encarga de analizar cada uno de los conjuntos de valoraciones. Este bloque recorrerá todos ellos y se encargará de ir construyendo progresivamente el resultado final, que será un conjunto de filas (valoraciones) agrupadas por conjunto y ordenadas por puntuación.
Para conseguirlo, nada mejor que emplear una estructura iterativa LAMBDA/REDUCE. Lo interesante de la flexible REDUCE es que nos ofrece una gran libertad a la hora de construir el resultado devuelto por la función tras realizar un proceso repetitivo sobre un intervalo de datos; tanto da si necesitamos obtener un único valor numérico final como una matriz de cualquier tamaño, como ocurre en este caso de uso. ¡REDUCE puede con todo!
=LET(
// [BLOQUE 1] Variables, encabezado y argumentos opcionales
REDUCE(
fila_etiquetas;UNIQUE(CHOOSECOLS(filas_resultados;columna_conjunto));
LAMBDA(resultado;conjunto;
// [BLOQUE 3] Obtención de los mejor clasificados por conjunto
SI(
conjunto_reducido="";
resultado;
SI(resultado="";conjunto_reducido;{resultado;conjunto_reducido}))))
)
)
El valor inicial del acumulador en la estructura REDUCE es fila_etiquetas, variable que contendrá bien la primera fila del intervalo de entrada cuando este disponga de etiquetas en el encabezado, bien una cadena vacía en caso contrario.
REDUCE recorrerá todos los conjuntos, cuyos valores únicos extraemos a partir de la columna del intervalo de entrada donde están almacenados (argumento columna_conjunto de la función con nombre) utilizando UNIQUE y CHOOSECOLS.
Las expresiones del bloque 3, que encontraremos en la función LAMBDA convenientemente anidada en el interior del REDUCE, serán por su parte las encargadas de obtener las filas de los participantes mejor clasificados en cada conjunto de valoraciones. Lo has visto bien, esta es la parte donde realmente se produce la extracción de datos a partir de la tabla de valoraciones.
Por ahora solo necesito que te fijes en dos cosas que aparecen en la declaración de la función LAMBDA que tenemos ahora entre manos:
- El identificador resultado representa el valor del acumulador de REDUCE, sobre el que se va construyendo, iteración a iteración, el resultado que devolverá finalmente la función con nombre. Inicialmente el valor asignado al acumulador es fila_etiquetas.
REDUCE(fila_etiquetas;UNIQUE(CHOOSECOLS(... - El identificador conjunto contiene el valor del conjunto de comparación que se está tratando en cada iteración. Los hemos hemos obtenido con el UNIQUE de hace un momento.
☝ Regla nemotécnica: los identificadores correspondientes al acumulador y a los valores sobre los que se itera se declaran en el mismo orden tanto en la función REDUCE como en su LAMBDA correspondiente.
El resto del bloque 3 nos lo vamos a saltar por ahora en nuestro particular viaje hacia el corazón de la cebolla... digo fórmula.
La parte interesante la encontraremos en la parte final del fragmento de código del bloque 2 que te acabo de mostrar, concretamente en el interior del SI anidado:
- Si el conjunto de filas devuelto por la expresión que reside dentro del bloque 3 (conjunto_reducido) no contiene fila alguna (ninguno de los participantes seleccionados se encuentra entre los primeros puestos de la clasificación del conjunto), el resultado calculado en iteraciones anteriores no debe modificarse. En esa situación se devolverá el valor previo del acumulador, es decir, resultado.
- En caso contrario, se actualizará el valor del acumulador con las filas obtenidas por el bloque 3 en la iteración actual de acuerdo con la siguiente lógica:
- Si el acumulador está vacío se sobreescribirá sin más con la matriz de filas obtenida en conjunto_reducido.
- En caso contrario, estas filas se añadirán a las almacenadas previamente en el acumulador utilizando esta expresión de composición matricial:
{resultado;conjunto_reducido}También podríamos haber utilizado la más novedosa función VSTACK para actualizar el acumulador, pero por alguna razón me resisto a abandonar las viejas costumbres... casi siempre.💡 #GoogleSheets tip:
— Pablo Felip (@pfelipm) February 13, 2023
Why use the sparkling new VSTACK / HSTACK functions instead of just composing arrays with { , ; \ } ⁉️
Because they support arrays of different dimensions, even though the built-in help doesn't say 💣
And btw, 👌 great contextual error messages! pic.twitter.com/8SRmjwtxje
Si quieres saber más sobre cómo funciona REDUCE, te invito nuevamente a que (re)visites mi artículo previo sobre la construcción de la función con nombre SUBMATRIZ, concretamente esta sección donde se plantea y resuelve un caso de uso que explota las capacidades de esta potente función. También puedes leer sobre las funciones auxiliares Lambda en esta otra publicación más antigua:
Ya solo nos queda el último bloque, anidado —insisto— en el interior del bloque 2. Hemos alcanzado por fin el corazón de nuestra cebolla formular.
Bloque 3 | Mejores clasificados en cada conjunto de valoración
Esta parte es probablemente la más compleja de toda la expresión. Pero que eso no te intimide, vamos a por ella con todo.
=LET(
// [BLOQUE 1] Variables, encabezado y argumentos opcionales
REDUCE(
// [BLOQUE 2] Iteración sobre los conjuntos de valoraciones
LAMBDA(resultado;conjunto;
LET(
conjunto;SORT(
FILTER(
filas_resultados;
CHOOSECOLS(filas_resultados;columna_conjunto)=conjunto
);columna_valoracion;NO(mayor_es_mejor));
conjunto_reducido;SI.ERROR(
FILTER(
conjunto;
(JERARQUIA(
CHOOSECOLS(conjunto;columna_valoracion);
CHOOSECOLS(conjunto;columna_valoracion);
NO(mayor_es_mejor))<=umbral_clasificacion) *
(CONTAR.SI(
lista_participantes;
CHOOSECOLS(conjunto;columna_participante))>0)));
// [BLOQUE 2] Construcción del resultado
))
))
Este bloque recurre a la función FILTER en un proceso de filtrado en dos pasos:
- En el primero se discriminan las filas de la tabla de valoraciones que forman parte del conjunto de comparación actual. No te pierdas, nos encontramos en el interior del REDUCE del bloque 2 que itera sobre los distintos conjuntos de valoraciones.
- El segundo, por su parte, que recibe como intervalo de datos de entrada el resultado del primer filtro, es el más delicado. En el se utiliza un criterio de filtrado compuesto por dos cláusulas lógicas que deben satisfacerse simultáneamente:
- En la primera interviene la función JERARQUIA. Con ella se limita el resultado a las filas que contienen puntuaciones dentro del umbral establecido en la clasificación.
- La segunda se utiliza para descartar las filas que contienen las puntuaciones de entidades en las que no estamos interesados.
☝ Tal vez te preguntes por qué razón no consolidamos en una única función FILTER las tres condiciones de filtrado anteriores que operan sobre el conjunto de valoraciones, la posición en la clasificación y la lista de participantes seleccionados. ¡Es una buena pregunta!
De hacerlo de ese modo, aparentemente más natural, la función JERARQUIA tendría en cuenta todas las puntuaciones de la tabla, dado que las tres cláusulas de la condición del FILTER operarían sobre el conjunto de datos de entrada completo, en lugar de hacerlo únicamente sobre las pertenecientes a un conjunto de valoraciones específico. Esto hace que la estrategia de filtrado en dos fases finalmente implementada sea necesaria. Y para dar nombre al resultado intermedio, del primer filtro, LET nos viene estupendamente.
Así es, a veces las cosas no son lo que parecen, ni el camino más fácil es el más correcto.
Es precisamente en esta segunda expresión de filtrado donde nos encontraremos con unas cuantas cosas que merecen cierta atención.
La función FILTER presenta ciertas peculiaridades, de las que ya hablamos también en un artículo previo:
📝 Resumiendo filas relacionadas en las nuevas Tablas de Google Sheets (+ una extraña peculiaridad)
1️⃣ La primera de ellas es que en FILTER no es posible utilizar expresiones lógicas compuestas con las funciones lógicas O, Y o NO. Ocurre exactamente lo mismo cuando se usan en expresiones envueltas por ARRAYFORMULA.
Sin embargo, la condición del segundo FILTER debe ser necesariamente doble (posición en la clasificación dentro de cierto umbral + participantes seleccionados). ¿La solución? Pues una vieja conocida: sustituir la función O por una suma o la función Y (como aquí) por un producto de cláusulas lógicas.
Y(exp_lógica_1; exp_lógica 2) → (exp_lógica 1) * (exp_lógica 2)O(exp_lógica_1; exp_lógica 2) → (exp_lógica 1) + (exp_lógica 2)La única precaución que deberemos adoptar es la de utilizar preventivamente sendos paréntesis para encerrar cada cláusula. El mecanismo de coerción de tipos del motor del lenguaje de fórmulas de Google Sheets, que interpreta valores numéricos como lógicos (booleanos) y viceversa, se encargará del resto. Esta característica también la usaremos en nuestro beneficio en la función JERARQUIA que te muestro justo a continuación, en cuyo tercer parámetro (es_ascendente) alimentaremos con valores lógicos en lugar de los numéricos esperados (0, 1).
☝ Realmente no es necesario usar el [*] con la función FILTER para exigir el cumplimiento simultáneo de varias condiciones. Esta función admite múltiples cláusulas condicionales como argumentos, que se combinan en una «Y» lógica, por lo que bastará con introducirlas separadas por punto y coma [;].
No obstante, conocer este pequeño truco en su dimensión más general puede resultarte de ayuda en otras situaciones, por ejemplo cuando te las veas con una expresión en la que intervenga ARRAYFORMULA, que tampoco se lleva bien con las funciones lógicas del lenguaje de fórmulas de Google Sheets.
2️⃣ La segunda particularidad puede resultar de entrada un tanto más confusa, si cabe. Hagamos zoom sobre la cláusula lógica que aplica el criterio de clasificación:
JERARQUIA(
CHOOSECOLS(conjunto;columna_valoracion);
CHOOSECOLS(conjunto;columna_valoracion);
NO(mayor_es_mejor)
)<=umbral_clasificacion
¿Qué demonios está pasando aquí 😵💫? ¿Cómo pueden ser idénticos los dos primeros argumentos?
Veamos, el segundo argumento de JERARQUIA representa la columna de valoraciones del conjunto de datos obtenido por el fitro de la primera etapa 1. Pero por su parte, el primer argumento de JERARQUIA, que debería ser el valor buscado, es... ¡esa misma columna!
JERARQUIA(valor; datos; [es_ascendente])
Calma. Las expresiones condicionales utilizadas en las funciones FILTER se comportan de un modo análogo a cuando empleas ARRAYFORMULA. El segundo argumento de JERARQUIA no se ve afectado en absoluto, dado que ya es una matriz (la columna con las puntuaciones de un conjunto de valoraciones). El efecto sobre el primero, en cambio, es el de utilizar cada uno de los valores de la columna de puntuaciones del conjunto de valoraciones que se está analizando para calcular su posición en la clasificación... que si lo piensas, ¡es justo lo que pretendemos!
De hecho, se da una circunstancia similar en el segundo argumento (criterio) del CONTAR.SI que viene a continuación... y es que a veces las cosas sí son lo que parecen, aunque resulten cacofónicas como en esta ocasión 😉.
Todo correcto, prosigamos.
3️⃣ He dejado para el final no tanto una rareza como una sorprendente curiosidad. La última condición que se aplica en la segunda etapa de filtrado es la que se encargará de limitar los resultados a la lista de participantes seleccionados. Esto se consigue, de un modo absolutamente convencional y carente de emoción alguna, por medio de un simple recuento de valores:
CONTAR.SI(lista_participantes;CHOOSECOLS(conjunto;columna_participante))>0)
Pero sorpresas nos da la vida. ¿Sabías que Google Sheets oculta una función no documentada que hace ella solita justo eso?
CONDITION_ONE_OF_RANGE(valor_buscado; valor1; valor2...)
Al igual que en CHOOSECOLS/ROWS, cada argumento valorN puede ser un elemento único o una expresión matricial. La función devolverá un valor lógico VERDADERO cuando valor_buscado se encuentre entre los facilitados y FALSO en caso contrario.
Utilizándola en nuestra función con nombre JERARQUIA.MEJORES, el criterio que limita los resultados a una lista de participantes se podría haber escrito así de rico:
CONDITION_ONE_OF_RANGE(
CHOOSECOLS(conjunto;columna_participante);lista_participantes
)
Esta función supersecreta no figura en la ayuda oficial, ni tampoco aparece en el asistente de autocompletado de fórmulas. Pero está ahí. Y funciona. Aunque tal vez no para siempre, por lo que tras sopesar pros y contras, he optado por no recurrir ella en la implementación final.
⚠️ Explotar las características no documentadas de una herramienta para conseguir cosas que de entrada no parecen posibles mola mucho. Estas pequeños tesoros ocultos están por todas partes: Notion, Coda, AppSheet, Apps Script... Pero pueden convertirse en pequeños regalos envenenados, susceptibles de sembrar el caos y la destrucción en tu vida. Conozco historias para no dormir. ¡Usa sus dones de manera responsable!
La función completa
Pongámoslo todo junto:
JERARQUIA_MEJORES(
tabla_resultados; columna_conjunto; columna_participante;
columna_valoracion; umbral_clasificacion; mayor_es_mejor;
lista_participantes; encabezados)
=LET(
mayor_es_mejor;SI(ESLOGICO(mayor_es_mejor);mayor_es_mejor;VERDADERO);
encabezados;SI(ESLOGICO(encabezados);encabezados;FALSO);
fila_etiquetas;SI(
encabezados;
CHOOSEROWS(tabla_resultados;1);
"");
filas_resultados;SI(
encabezados;
CHOOSEROWS(
tabla_resultados;
SEQUENCE(FILAS(tabla_resultados)-1;1;2;1));
tabla_resultados);
lista_participantes;SI.ERROR(SI(
ESBLANCO(lista_participantes);
UNIQUE(CHOOSECOLS(filas_resultados;columna_participante));
lista_participantes);lista_participantes);
REDUCE(
fila_etiquetas;UNIQUE(CHOOSECOLS(filas_resultados;columna_conjunto));
LAMBDA(resultado;conjunto;
LET(
conjunto;SORT(
FILTER(
filas_resultados;
CHOOSECOLS(filas_resultados;columna_conjunto)=conjunto
);columna_valoracion;NO(mayor_es_mejor));
conjunto_reducido;SI.ERROR(
FILTER(
conjunto;
(JERARQUIA(
CHOOSECOLS(conjunto;columna_valoracion);
CHOOSECOLS(conjunto;columna_valoracion);
NO(mayor_es_mejor))<=umbral_clasificacion) *
(CONTAR.SI(
lista_participantes;
CHOOSECOLS(conjunto;columna_participante))>0)));
SI(
conjunto_reducido="";
resultado;
SI(resultado="";conjunto_reducido;{resultado;conjunto_reducido}))))
))
¡Benditas sean esas formidables funciones con nombre capaces de encapsular engendros como este para que podamos reutilizarlos sin morir en el intento!
Comentarios finales y siguientes pasos
Como de costumbre, aquí tienes la hoja de cálculo que he utilizado para preparar este artículo.
👉 Fx con nombre JERARQUIA.MEJORES 👈
Además de la función con nombre JERARQUIA_MEJORES que hemos construido hoy, encontrarás otras tres versiones, dos ellos menos elaboradas de las que no he hablado en el artículo, y una tercera que utiliza la función CONDITION_ONE_OF_RANGE. Échale un vistazo si quieres a la ayuda contextual que he preparado para todas ellas para conocer sus peculiaridades... pero no les dediques demasiado tiempo porque creo que no son importantes.
Con este artículo y los tres anteriores que he publicado a lo largo de las últimas semanas, doy por finalizada la serie (más o menos) orientada a demostrar el uso de algunas de las nuevas características que han ido llegando a Google Sheets (sintaxis Lambda, nuevas funciones, Tablas). Espero que te hayan gustado.
Voy a darles un descanso momentáneo a las hojas de cálculo de Google, al menos por lo que hace a la producción de artículos más o menos extensos como los publicados recientemente. Me apetece cambiar un poco de tercio. Atento/a a mis redes sociales (X, LinkedIn), ¡artículos sobre Notion y Apps Script a la vista!
Como siempre, gracias por acompañarme una vez más.
Comentarios