
Mejorando las funciones CHOOSECOLS/ROWS de Google Sheets con Apps Script

Con las funciones CHOOSECOLS y CHOOSEROWS integradas en el lenguaje de fórmulas de Google Sheets podemos diseccionar un intervalo de datos de un modo cómodo y directo. De hecho, la primera de estas dos funciones incluso puede ser una mejor alternativa a la todopoderosa QUERY en determinados escenarios.
¿Pero qué pasa cuando nos topamos con intervalos de datos monstruosos, con decenas o incluso cientos de columnas? En esa situación, enumerar en nuestras fórmulas, una a una, los índices de todas las columnas cuyos datos deseamos obtener no es aceptable.
¿Podemos solucionarlo? Por supuesto 😏, con una manita de Apps Script, que nunca viene mal. Acompáñame mientras construimos juntos la función personalizada...
CHOOSECOLSROWS
Te garantizo un artículo totalmente libre de contenidos sobre IA, cosa que en los tiempos que corren ya es mucho decir 😈.
TABLA DE CONTENIDO
Las funciones personalizadas Apps Script
He sido y soy un fan casi incondicional de las funciones personalizadas construidas con Apps Script. Y es que aunque el lenguaje de fórmulas del editor de hojas de calculo de Google es ya de por sí considerablemente rico, siempre nos falta justo esa que nos empeñamos en necesitar.
Las funciones personalizadas GAS (simplemente funciones personalizadas en adelante) presentan algunas particularidades:
- Enriquecen el lenguaje de fórmulas de Google Sheets con nuevas funciones que se construyen mediante código Apps Script, ya sabes: bueno, bonito y barato.
- Su tiempo máximo de ejecución es de 30 segundos en cada celda en la que se utilizan.
- Se ejecutan sin autorización y por tanto solo pueden usar un conjunto limitado de los servicios Apps Script disponibles, básicamente aquellos que no acceden a la información del usuario. Por esa razón, no es necesario que el usuario autorice de manera explícita el acceso a sus datos personales , como sí ocurre normalmente con otros scripts GAS.
- Lo habitual es que realicen operaciones únicamente sobre los datos que se les pasan como parámetros, sean estos referencias o valores explícitos, aunque lo cierto es que también pueden diseñarse de manera que utilicen otra información contenida en las hojas de cálculo en las que residen. Te muestro un ejemplo de ello en un momento.
- No pueden en ningún caso alterar el contenido de otras celdas distintas a las que acogen los valores que devuelven como resultado. Puede tratarse de valores únicos o de matrices de valores, que se extenderán en su caso del modo esperable en una hoja de cálculo a las celdas adyacentes —abajo / derecha— a la que contiene la fórmula.
- No pueden acceder a la información contenida en hojas de cálculo distintas a aquella en la que reside su código o en otros documentos alojados en Google Drive. No obstante, sí son capaces de conectar con servicios web externos utilizando URL Fetch, lo que abre la puerta a intentar ciertas fechorías, como por ejemplo potenciarlas mediante APIs de terceros.
- Pueden distribuirse fácilmente alojadas en plantillas de hoja de cálculo de Google o, mucho mejor, dentro de complementos de tipo editor para ellas (los complementos antiguos, para entendernos).
Lo cierto, sin embargo, es que desde el lanzamiento de las también muy notables funciones con nombre, que son cosa parecida pero no totalmente equivalente, es probable que sea preferible utilizar estas últimas para expandir el catálogo de funciones de las hojas de cálculo.
Lo anterior no es óbice para que las viejas funciones personalizadas sigan siendo mejor opción que las modernas funciones con nombre a la hora de implementar ciertas cosas, por ejemplo cuando la función que pretendemos construir requiere un código más complejo o simplemente extenso. Y como muestra, un botón.
En efecto, tanto la función LET como toda la caterva de funciones LAMBDA han supuesto un alivio innegable, y también una alegría enorme, por qué no decirlo, para todos esos y esas innumerables frikis de Google Sheets entre los que, cómo no, me cuento. Pero AppsScript —JavaScript en definitiva— sigue siendo un lenguaje más rico y versátil, con el que personalmente me encuentro más cómodo pensando en los términos algorítmicos característicos de un lenguaje estructurado.
Además, el potente y moderno editor de desarrollo integrado Apps Script resulta mucho más cómodo para trabajar que el ampliable, pero exiguo en comparación, panel de edición de funciones con nombre.
☝ En esta sección de un artículo previamente publicado en este espacio ya analizaba de manera comparada funciones personalizadas y funciones con nombre, tal vez quieres echarle un vistazo breve antes de continuar. Yo te espero por aquí.
Realmente una función personalizada es un artefacto Apps Script muy simple. De hecho, es una de las primera cosas que se construyen en esos entrañables talleres de iniciación a GAS. Su mecanismo interior, extremadamente sencillo, resulta muy accesible para los recién llegados a Apps Script, en especial para aquellos que ya son usuarios de hojas de cálculo. Afirmativo: GAS & hojas de cálculo son una pareja casi perfecta.
De hecho, basta con abrir el editor de código en Extensiones → Apps Script, crear una función (con un nombre aparente siempre que puedas 😜) que realice algún cálculo en su interior a partir de ciertos parámetros de entrada y devuelva un resultado. Y ya tienes tu flamante función, que puedes invocar de manera natural en cualquiera de las fórmulas de tus hojas de cálculo. Así de inmediato (chúpate esa, Packs de Coda 😘).
☝ Aunque es menos habitual, también hay funciones que no reciben parámetros.
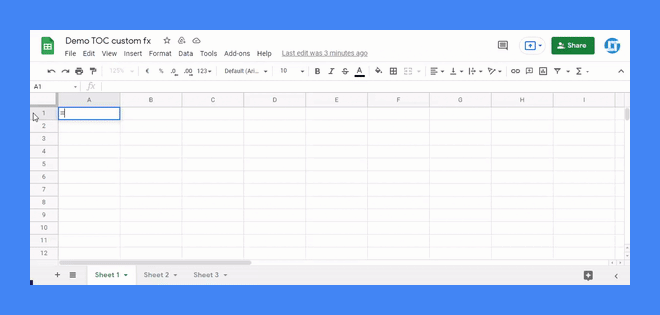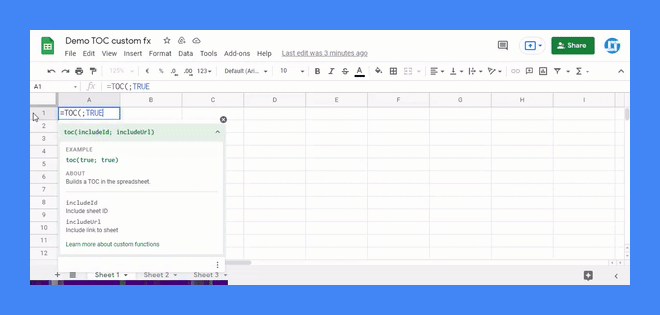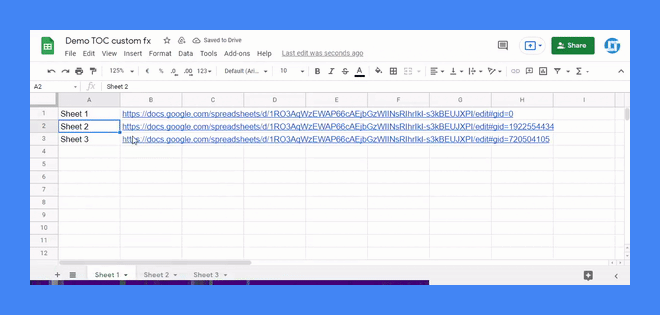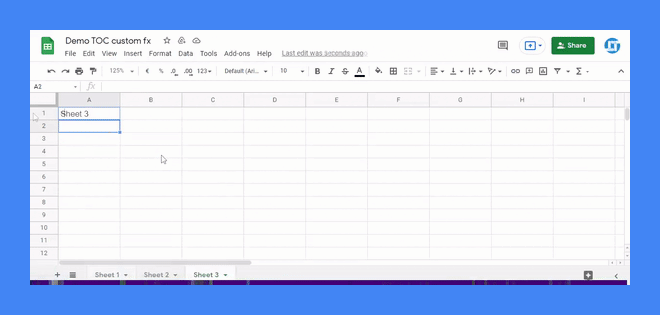
Por ejemplo, esto es todo lo que hace falta para montar una función personalizada que genere una lista con los nombres de todas las pestañas de tu hoja de cálculo. Sí, una especie de tabla de contenido en la que hasta puedes hacer clic en el nombre de una hoja para saltar cómodamente a ella.
/**
* Builds a TOC in the spreadsheet.
* @param {true} includeId Include sheet ID
* @param {true} includeUrl Include link to sheet
* @return List of [Sheet name, Sheet ID, Sheet URL]
* @customfunction
*/
function TOC(includeId, includeUrl) {
const ss = SpreadsheetApp.getActive();
const baseUrl = ss.getUrl();
const toc = [];
ss.getSheets().forEach(sheet => {
const rowResult = [];
rowResult.push(sheet.getName());
if (includeId) rowResult.push(sheet.getSheetId());
if (includeUrl) rowResult.push(baseUrl + '#gid=' + sheet.getSheetId());
toc.push(rowResult);
});
return toc;
}
Los comentarios en las líneas 1 - 7 son los responsables de que nuestra función personalizada de ejemplo, denominada TOC (table of contents), disponga incluso de una práctica y familiar ayuda contextual. Para eso, los comentarios deben ajustarse a una interesante especificación denominada JSDoc, claro está.
☝ Si te interesa el tema, te remito a mis artículos previos sobre funciones personalizadas. En ellos encontrarás abundantes detalles de diseño e implementación, especialmente en los repositorios GitHub de las funciones DESACOPLAR/ACOPLAR y MEDIAMOVIL. Te advierto no obstante que esos son desarrollos que ya tienen algún tiempo y ahora no hago las cosas de la misma manera.
¡Vamos con eso de seleccionar columnas a lo grande!
La función personalizada SUPERCHOOSECOLS
Tengo que decir que la chispa que me llevó a está función la encendió mi querido amigo y compañero de edusaraos en los tiempos recientes, BalBino Fernández (siempre con bes mayúsculas por razones que aún no me ha desvelado 🙃).
Fue en el transcurso de una llamada en la que andábamos discutiendo no sé muy bien de qué, y probablemente también hablando poco bien de alguien 🤐. BalBino deslizó muy sibilinamente en la conversación que andaba a la gresca con una de esas hojas de cálculo inabarcables que aparecen en las peores pesadillas y necesitaba algo mejor que un viejo pero confiable QUERY para reunir en otro confín de sus hojas unas buenas docenas de columnas rebeldes.
Me cuesta negarme a ayudar a un amigo, especialmente cuando eso constituye una oportunidad para quedar como un tipo listo, aún más si hay Apps Script por medio, así que mi respuesta fue:
—Sujétame el cub...
Bueno, más bien:
—Claro, chiqui, eso te lo monto en cerocoma.
Y unos minutos después, ambos contemplábamos este artefacto en una hoja de cálculo compartida:
SUPERCHOOSECOLS
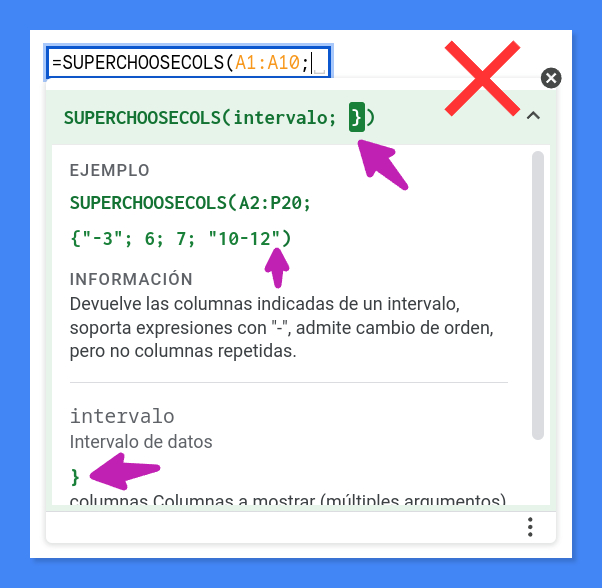
(intervalo; columnas; mas_columnas...)

Bueno, creo que este ha sido todo el contexto que te voy a dar, que igual ni lo querías. Lo siento, pero cada vez me cuesta más escribir un artículo técnico de manera seria y formal. Hablemos ya sin más rodeos del diseño y la implementación de la función personalizada SUPERCHOOSECOLS.
Esta función devuelve las columnas de un intervalo de entrada (parámetro o argumento 1, intervalo) indicadas mediante el parámetro o argumento 2 (columnas). Las columnas que se desea extraer pueden indicarse de dos modos distintos:
- Mediante una lista de índices numéricos separados por comas. Evidentemente, estos índices representan la posición de una columna dada desde la situada más a la izquierda del intervalo de celdas facilitado en el primer parámetro, comenzando por 1.
- Mediante una lista de expresiones alfanuméricas (cadenas de texto, para entendernos) como «a-b», donde a y b son índices de columna. Aquí es donde está la gracia, claro está, porque de este modo evitamos tener que enumerar un número potencialmente excesivo de columnas, una a una.
La función admite que los elementos que designan las columnas, sean del tipo [A] (numéricos) o [B] (cadenas de texto), puedan combinarse entre sí libremente, por ejemplo:
1; 3; 5; "7-10"
También pueden enumerarse en cualquier orden, lo que permite desordenar las columnas del intervalo devuelto por la función.
1; 3; "7-10"; 5
La función ignorará los índices de columna repetidos, tanto si han sido indicados de manera explícita (valor numérico) como implícita (cadena de texto de intervalo).
Venga, el código, rapidito:
/**
* ¡Primer intento!
* Devuelve las columnas indicadas de un intervalo, soporta expresiones con "-",
* admite cambio de orden, pero no columnas repetidas.
*
* @param {A2:P20} intervalo Intervalo de datos
* @param {3; 5; 1} columnas Columnas a mostrar (múltiples argumentos)
*
* @customfunction
*/
function SUPERCHOOSECOLS(intervalo, ...columnas) {
const columnasConjunto = new Set();
columnas.forEach(columna => {
if (typeof columna == 'number') {
columnasConjunto.add(columna);
console.info('Añadiendo: ' + columna);
}
else if (typeof columna == 'string') {
const inicio = columna.split('-')[0];
const fin = columna.split('-')[1];
for (let i = Number(inicio); i <= Number(fin); i++) columnasConjunto.add(i);
}
});
return intervalo.map(fila => {
const filaResultado = [];
columnasConjunto.forEach(col => filaResultado.push(fila[col - 1]));
return filaResultado;
});
}
Fíjate en cómo logramos que nuestra función admita como parámetros de entrada un número indeterminado de índices numéricos o de expresiones alfanuméricas para designar un conjunto de columnas. Para ello se utiliza la sintaxis de parámetros rest (línea 11).
function SUPERCHOOSECOLS(intervalo, ...columnas) { }☝ No confundas esta sintaxis con la de extensión (que basura de traducción para spread acabo de perpetrar, pardiez 😅). Ambas se articulan utilizando el mismo operador [...], pero dependiendo del contexto, esos inocentes puntos suspensivos tienen un significado diametralmente opuesto, algo así como extensión vs. compresión).
A continuación (línea 13 - 24 ), se inicializa la variable columnasConjunto, que como su nombre sugiere sostiene una estructura de datos de tipo conjunto, y se introducen en ella todos y cada uno de los elementos utilizados para designar las columnas seleccionadas. Los conjuntos garantizan que no habrá elementos repetidos —columnas— en su interior, algo que en aquel momento parecía una buena idea.
El bucle que lee el parámetro columnas identifica si cada elemento es un valor numérico o una cadena de texto. En el primer caso (líneas 15 - 18), simplemente lo añade sin más al conjunto.
En el segundo (líneas 19 - 23), se emplea la función split() para extraer las subcadenas de texto inmediatamente a la izquierda y a la derecha del guión separador, que una vez forzadas a sus correspondientes valores numéricos con Number() podrán ser utilizadas directamente para recuperar los valores de las columnas del intervalo de datos designado.
☝ A veces resulta mucho más cómodo tirar de la función String.prototype.split() que vérselas con las a menudo temibles expresiones regulares. Como una vez dijo el gran Jamie Zawinski, «si tienes un problema y decides usar expresiones regulares para resolverlo, entonces ya tienes dos».
Ya solo queda, en las líneas 26 - 30, recorrer las filas del intervalo de datos de entrada y hacer un poco de magia de primero de Hogwarts con los índices de las columnas para que la función devuelva una matriz de datos compuesta únicamente por los valores deseados.
☝ Los conjuntos de JavaScript no pueden iterarse con la ubicua función map(), pero sí usando for...of o su método específico forEach(). Y te lo recuerdo aquí y ahora porque yo olvido este detalle con frecuencia y termino convirtiendo innecesariamente conjuntos en vectores antes de intentar recorrerlos.
const columnasVector = [...columnasConjunto];
Veamos un ejemplo sobre una hoja de cálculo no tan tenebrosa, lo admito, como la aportada por BalBino.
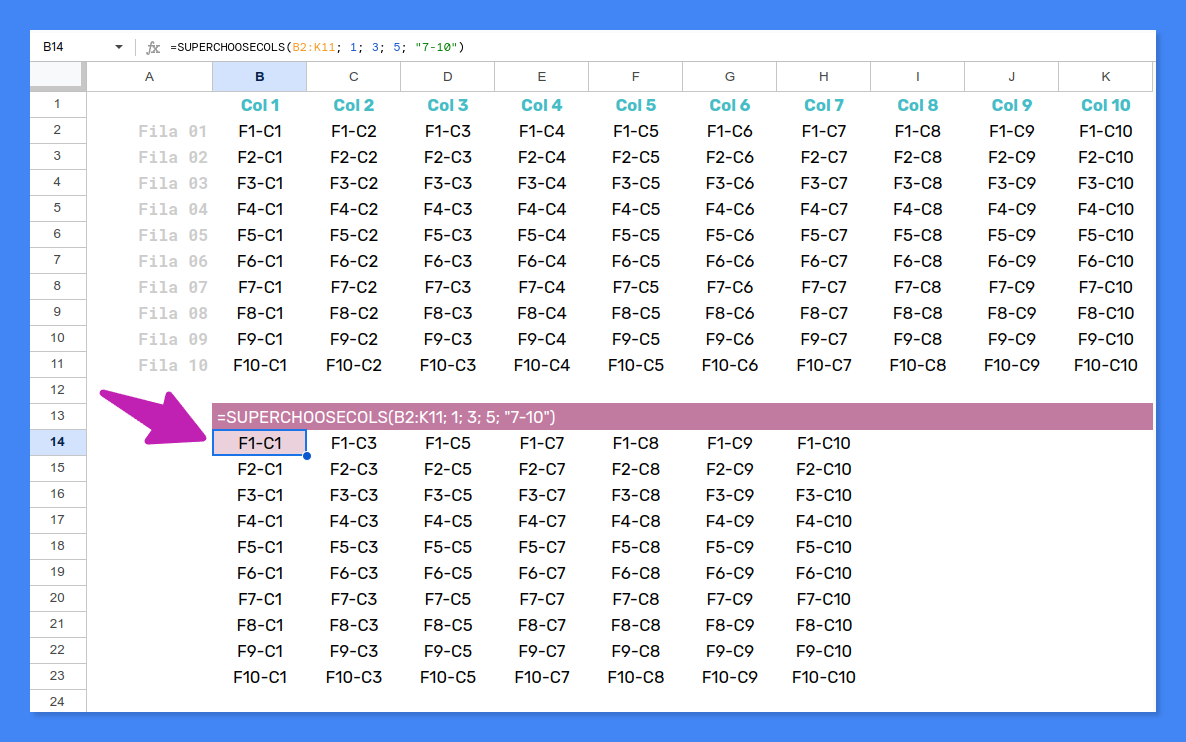
=SUPERCHOOSECOLS(B2:K11; 1; 3; 5; "7-10")
No está mal para 19 líneas de código (descontando comentarios y líneas en blanco), ¿verdad?
Bueno, lo cierto es que esto es mejorable. Muy mejorable.
Y como no puedo dejar de complicarme la vida cada vez que tengo la oportunidad de enredar con Apps Script (también con otras cosas 😆), no tuve más remedio que darle un par de vueltas, en solitario ya, al asunto en su momento (o ahora, que me estoy liando con tanto salto temporal).
Si te gustan las funciones de #GoogleSheets:
— Pablo Felip (@pfelipm) October 2, 2023
CHOOSECOLS()
CHOOSEROWS()
...te va a encantar esta función personalizada #AppsScript:
HDCPLUS_SUPERCHOOSE() 😏
Selecciona:
⭐️ Columnas y filas
⭐️ Usando intervalos abiertos o cerrados: x-y, x-, -y
⭐️ Usando etiquetas de encabezado https://t.co/N44D18vXup pic.twitter.com/pgHjZ0Gyc9
La función personalizada HDCP_CHOOSECOLSROWS
La función previa hace lo que tiene que hacer, facilitar la selección de columnas de un intervalo de datos para mostrarlas en el orden que nos apetezca. Pero:
- No admite columnas repetidas, como sí hace la función nativa CHOOSECOLS.
- No es capaz de seleccionar filas, por lo que no sustituye en modo alguno a CHOOSEROWS, que junto con la anterior hacen una pareja entrañable.
- No permite especificar intervalos abiertos, por ejemplo "-5" (hasta la fila o columna 5) o "10-" a partir de la fila o columna 10.
¡Vamos a crear una nueva versión de esta función personalizada que solvente los inconvenientes anteriores!
Y además, la dotaremos de un nuevo superpoder 🦸🏼, un modo adicional de selección de columnas y filas por coincidencia de las etiquetas de encabezado, que puede resultar útil en determinadas situaciones.
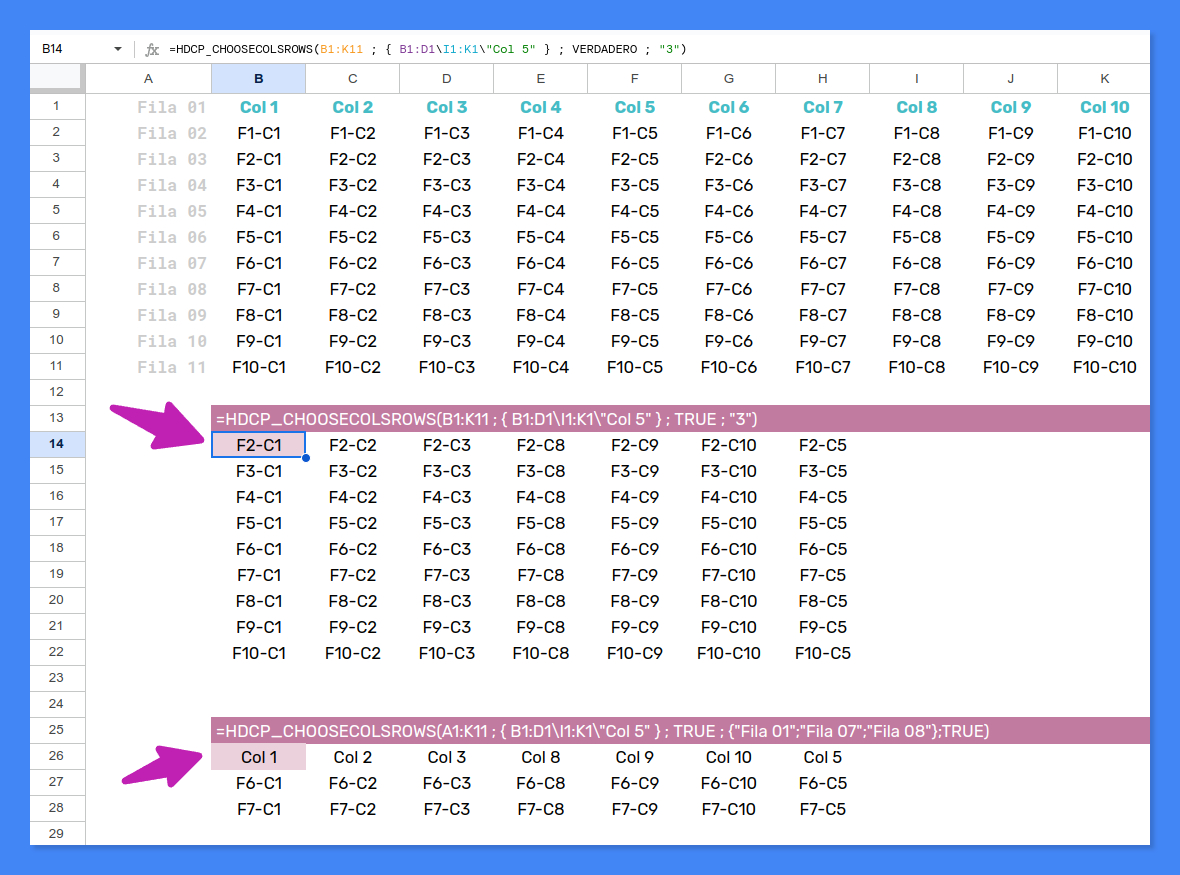
HDCP_CHOOSECOLSROWS
(intervalo; columnas; usa_etiquetas_col; filas; usa_etiquetas_fil)
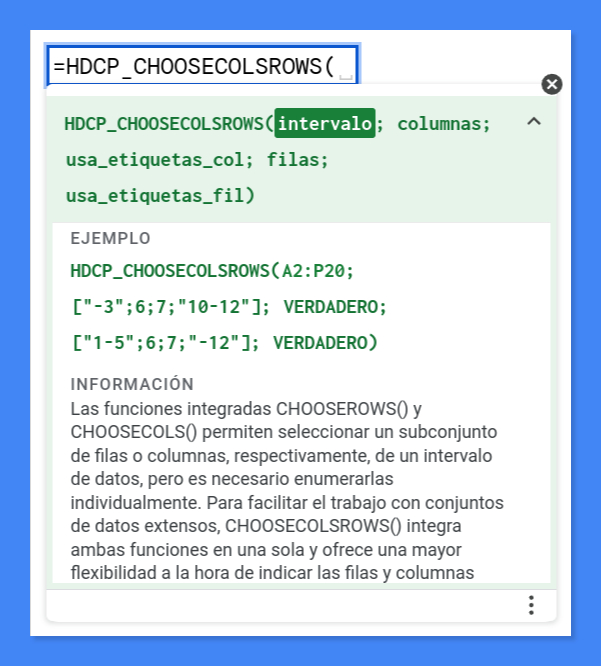
Tal vez te llame la atención el ejemplo de uso que se aprecia en la captura anterior. En él se utilizan corchetes [...] para denotar los vectores que enumeran las columnas y filas seleccionadas. Me refiero a esto:
["-3"; 6; 7; "10-12"]
["1-5"; 6; 7; "-12"]
Como probablemente sepas, el lenguaje de fórmulas de Google Sheets usa llaves {...}, en lugar de corchetes, para construir expresiones matriciales como las dos anteriores:
{"-3"; 6; 7; "10-12"}
{"1-5"; 6; 7; "-12"}
Por un lado, la especificación JDDoc utiliza la etiqueta @param para definir y documentar los parámetros de las funciones. Esto se hace indicando a continuación su tipo por medio de una serie de palabras reservadas entre llaves.
@param {Array<number|string>} vector_columnas
Por otro lado, resulta que el particular mecanismo empleado por las funciones personalizadas Apps Script requiere que se utilicen en su lugar valores literales dentro de esas etiquetas @param. Estos valores literales declarados aquí son utilizados oportunamente para generar de manera automática los ejemplos de uso que aparecen en la ayuda contextual. Si respetamos la convención del lenguaje de fórmulas de Sheets, la cosa quedaría así:
@param {{"-3"; 6; 7; "10-12"}} vector_columnas
Pero aquí tenemos un problema. La presencia en este caso de esas llaves duplicadas en la declaración JSDoc del parámetro hace que este mecanismo deje de funcionar correctamente, como puedes apreciar en la captura siguiente, cosa que me parece aún menos aceptable que utilizar un símbolo equívoco en los ejemplos que se facilitan en la ayuda de la función.
Por esta razón, he optado por utilizar corchetes para denotar los parámetros de tipo matriz, corchetes que en la propia ayuda contextual de la función se advierte que deben ser sustituidos por llaves.
La nueva versión de la función SUPERCHOOSECOLS debe ahora contemplar un número mayor de funcionalidades, por lo que la implementación resulta más extensa y complicada.
Para facilitar su análisis identificaremos 4 bloques diferenciados:
- Definición de la función, que incluye los comentarios JSDoc gracias a los que se articula la ayuda contextual.
- Control de parámetros.
- Función interna auxiliar que realiza la interpretación de los argumentos de selección de filas y columnas.
- Generación del intervalo de datos resultante y control de errores.
Definición de la función
En las líneas 1 - 48 nos encontramos con todo el bloque de comentarios y la propia declaración de la función, que ha sido rebautizada como HDCP_CHOOSECOLSROWS.
/**
* Las funciones integradas CHOOSEROWS() y CHOOSECOLS() permiten seleccionar un subconjunto de filas
* o columnas, respectivamente, de un intervalo de datos, pero es necesario enumerarlas individualmente.
* Para facilitar el trabajo con conjuntos de datos extensos, CHOOSECOLSROWS() integra ambas funciones
* en una sola y ofrece una mayor flexibilidad a la hora de indicar las filas y columnas que se desean extraer.
*
* Esta función crea una matriz a partir de las filas y columnas seleccionadas de un intervalo.
* Para designar las filas y columnas es posible utilizar: [I] una lista de valores numéricos que representan
* su posición desde el extremo superior izquierdo del intervalo de entrada (valores positivos) o inferior
* derecho (valores negativos), comenzando siempre por 1, por ejemplo: {1;2;4;-3;1}; [II] una lista de
* expresiones de texto entrecomilladas ("..-..") que denotan intervalos, abiertos o cerrados, por ejemplo:
* "3-12" (desde la fila/columna 3 a la 12), "-12" (desde la fila/columna 1 hasta la 12), "3-" o simplemente "3"
* (desde la fila/columna 3 hasta la última).
*
* Para seleccionar columnas y filas también es posible [III] utilizar una lista de etiquetas de texto, que se
* cotejarán con las que se encuentran en la fila o columna de encabezado, respectivamente, del intervalo de datos.
* Estas etiquetas pueden ser valores literales, referencias a otras celdas o una combinación de ambas cosas, por ejemplo:
* {"Nombre";"Edad";"Grupo"} o {B1:D1\I1:K1\"Grupo"}.
*
* Las listas de elementos de tipo [I] y [II] y [I] y [III] puede combinarse entre sí, pero [II] y [III] son
* mutuamente excluyentes.
*
* En todos los casos [I-III] las listas de elementos pueden construirse usando tanto vectores fila (como {1\2\3}) como
* columna (como {1;2;3}), pero no utilizando una combinación de ambos.
*
* Es posible designar una fila o columna más de una vez, lo que hará que se muestre repetida en la
* matriz devuelta por la función. También se admite el cambio de orden de las filas y columnas con respecto
* a sus posiciones en el intervalo de datos original.
*
* ⚠️IMPORTANTE⚠️: Los caracteres " [ " y " ] " que se muestran en la fórmula de EJEMPLO deben sustituirse por los
* símbolos " { " y " } " propios de la sintaxis de matrices de Google Sheets.
*
* @param {A2:P20} intervalo Intervalo de datos del que extraer un subconjunto de filas y columnas.
* @param {["-3";6;7;"10-12"]} columnas Vector ({...\...} o {...;...}) de índices de columnas, comenzando por 1, intervalos de índices como cadenas de
* texto ("..-..") o etiquetas de encabezado de columna (1ª fila). Requiere que usa_etiquetas_col sea VERDADERO.
* Se seleccionarán todas las columnas si se omite.
* @param {VERDADERO} usa_etiquetas_col Activa el modo de selección de columnas usando las etiquetas en los encabezados de columna (1ª fila) del intervalo.
* La comparación es estricta y diferencia mayúsculas de minúsculas (VERDADERO o [FALSO]).
* @param {["1-5";6;7;"-12"]} filas Vector ({...\... } o {...;...}) de índices de filas, comenzando por 1, o intervalos de índices como cadenas de
* texto ("...-...") o etiquetas de encabezado de fila (1ª columna). Requiere que usa_etiquetas_fil sea VERDADERO.
* Se seleccionarán todas las filas si se omite.
* @param {VERDADERO} usa_etiquetas_fil Activa el modo de selección de filas usando las etiquetas en los encabezados de filas (1ª columna) del intervalo.
*
* @return Matriz de datos compuesta únicamente por las filas y columnas seleccionadas.
*
* @customfunction
*/
function HDCP_CHOOSECOLSROWS(intervalo, columnas, usa_etiquetas_col, filas, usa_etiquetas_fil) {
Sí, estoy de acuerdo. Esto es un mazacote de proporciones bíblicas que ciertamente ofrece cierta resistencia a ser leído.
Mazacote de los buenos, además, puesto que no hay forma —o al menos yo he sido incapaz de encontrarla — de conseguir insertar líneas en blanco para conseguir que el texto que en la ventana de ayuda contextual se muestre de un modo más legible.
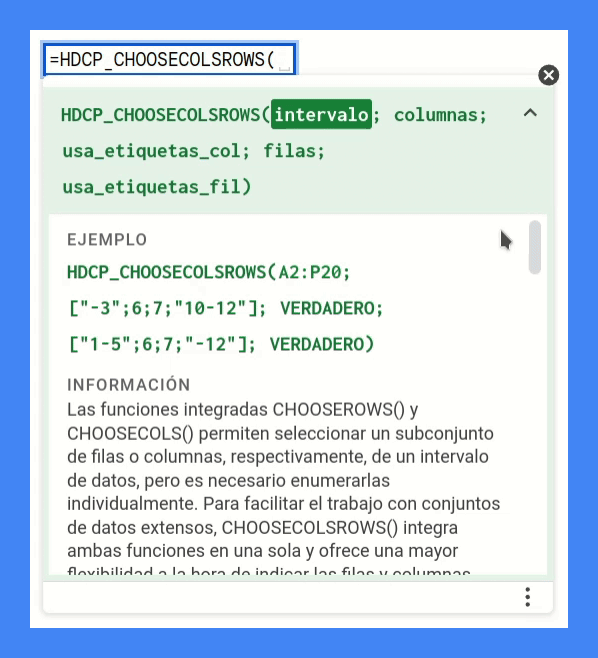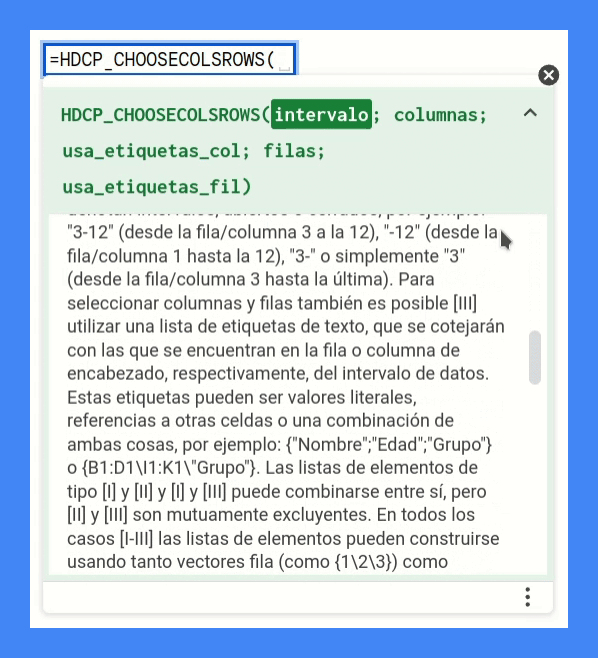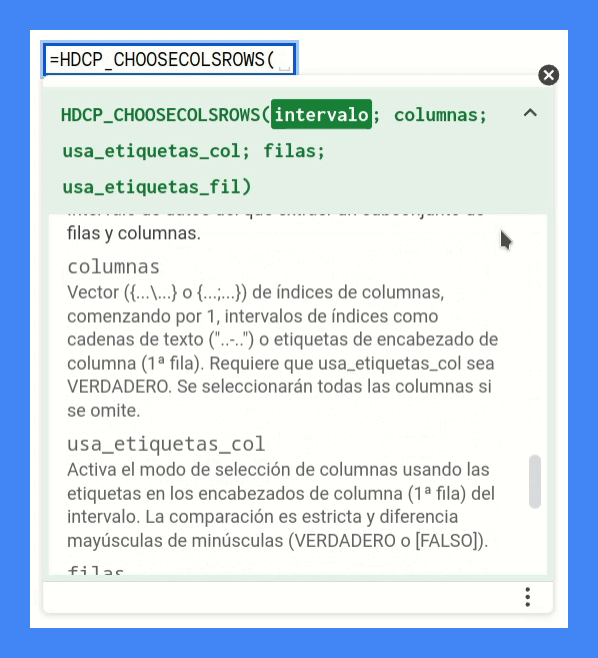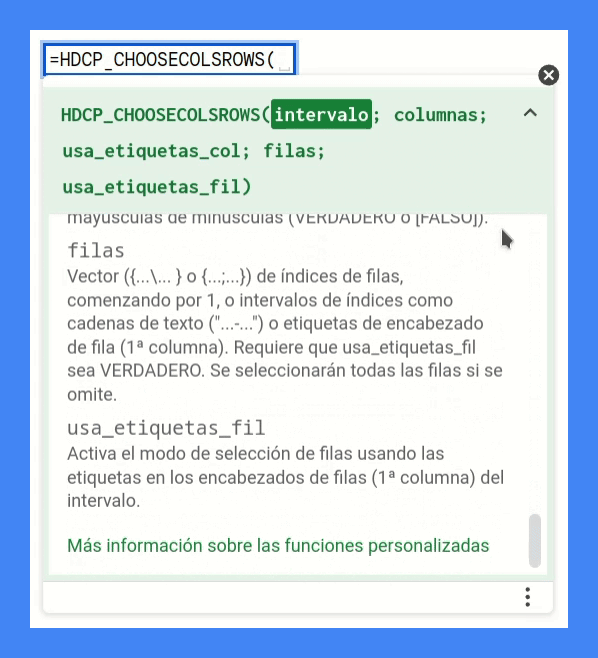
En mi defensa diré dos cosas.
La primera tiene que ver con el hecho de que la función tiene numerosos parámetros y distintas formas de uso que deben ser explicadas con cierto detalle.
| Parámetro | Descripción | Valor si se omite |
| intervalo | Intervalo del que se desea extraer un subconjunto de filas y/o columnas. | - |
| columnas | Columna o vector de columnas a extraer. | Se seleccionarán todas las columnas del intervalo. |
| usa_etiquetas_col | Si es VERDADERO, todas las expresiones de texto en el argumento columnas se entenderán no como indicadores de columna sino como etiquetas en la fila de encabezado del intervalo (fila 1). | FALSO |
| filas | Fila o vector de filas a extraer | Se seleccionarán todas las filas del intervalo. |
| usa_etiquetas_fil | Si es VERDADERO, todas las expresiones de texto en el argumento filas se entenderán no como indicadores de fila sino como etiquetas en la columna de encabezado del intervalo (columna 1). | FALSO |
Y la segunda es que cuando la programé aún no existía este artículo, por lo que mi particular TOC (y ahora no me refiero a una tabla de contenidos 😅) me impidió escribir una ayuda contextual más ligera.
Precisamente por todo esto, he preparado también esta página de ayuda, en la que encontrarás una descripción pormenorizada de cada uno de los argumentos de la función, ejemplos de uso y detalles adicionales.
☝ El orden en el que la función acepta los argumentos y su optatividad son cosas que deben considerarse cuidadosamente al diseñarla, puesto que pueden condicionar en gran medida su experiencia de uso.
En este caso, por ejemplo, he tenido en cuenta que el uso más común de la función será probablemente el de seleccionar un subconjunto de columnas indicando sus índices o intervalos de índices. Por esa razón:
- El parámetro columnas se indica antes que el parámetro filas al invocar la función y se ha hecho opcional, de modo que cuando se omita se incluyan todas las filas.
- El parámetro usa_etiquetas_col también es opcional y adoptará un valor FALSO al omitirse.
Estas decisiones de diseño de la función favorecen una sintaxis tan compacta como la que hubiéramos disfrutado con la menos potente y flexible SUPERCHOOSECOLS, a pesar de que ahora jugamos con un número mayor de argumentos.
=HDCP_CHOOSECOLSROWS(B2:K11; 1; 3; 5; "7-10")
Se trata de que el modo en que nuestras funciones personalizadas operan esté alineado todo lo posible con el comportamiento más razonable que se espera de ellas en cada circunstancia de uso.
Control de parámetros
Inmediatamente a continuación tenemos un puñado de líneas (50-56) que se encargan de realizar algunas comprobaciones básicas sobre los parámetros introducidos por el usuario al invocar la función para asegurarse de que tengan sentido.
function HDCP_CHOOSECOLSROWS(intervalo, columnas, usa_etiquetas_col, filas, usa_etiquetas_fil) {
// Comprobaciones iniciales sobre los argumentos
if (!intervalo.map) throw "Intervalo no válido";
if (columnas?.map && columnas.length > 1 && columnas[0].length > 1) throw 'El argumento «columnas» debe ser un valor único o un vector fila o columna de valores';
if (filas?.map && filas.length > 1 && filas[0].length > 1) throw 'El argumento «filas» debe ser un valor único o un vector fila o columna de valores';
// Conmutadores de selección por etiquetas, si no son booleanos (porque se ha introducido otra cosa o se han omitido), se asumen a falso
usa_etiquetas_col = typeof usa_etiquetas_col == 'boolean' ? usa_etiquetas_col : false;
usa_etiquetas_fil = typeof usa_etiquetas_fil == 'boolean' ? usa_etiquetas_fil : false;
En particular, se comprueba que:
- El intervalo del que se desean extraer un subconjunto de filas y columnas sea realmente una matriz de datos (línea 51).
- Cuando los argumentos que permiten seleccionar las filas y columnas son de tipo matricial se trate de vectores fila o columna, es decir, matrices unidimensionales (líneas 52-53).
- Los argumentos usa_etiquetas_col y usa_etiquetas_fil, que activan respectivamente los modos de selección de columnas y filas mediante las etiquetas de sus encabezados, adopten valores lógicos (booleanos). Es decir, algo como VERDADERO o FALSO (líneas 55 - 56).
Cuando se incumplan A o B la ejecución de la función terminará inmediatamente. Para ello el código lanzará sendas excepciones acompañadas de mensajes de error apropiados mediante throw. Estos mensajes llegarán al usuario del mismo modo que los emitidos por las funciones nativas del lenguaje de fórmulas de Google Sheets cuando se producen errores.
if (!intervalo.map) throw "Intervalo no válido";
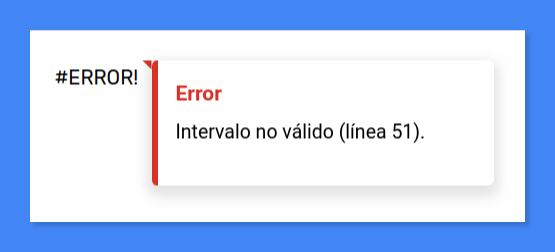
Una alternativa, en mi opinión menos satisfactoria, a la estrategia descrita anteriormente pasa por finalizar la ejecución devolviendo inmediatamente como resultado un mensaje de error, que quedará almacenado en el celda en la que se ha utilizado la fórmula como si del propio resultado se tratase:
if (!intervalo.map) return 'Intervalo no válido';
De hecho, yo solía hacer este tipo de cosas en mis primeras funciones personalizadas, pero en un momento dado caí en la cuenta de que tenía más sentido optar por finalizar la ejecución lanzando una excepción con la instrucción throw.
En este caso, la función no devolverá ningún valor cuando su resultado no pueda calcularse y aparecerá automáticamente en la celda el texto #ERROR!, que ahora se guardará en ella como un valor estándar de tipo error de Google Sheets. Este elemento vendrá acompañado, como hemos visto, de la reconocible escuadra roja en la esquina superior derecha de la celda característica de los errores de cálculo en las fórmulas nativas.
La comprobación C, por su parte, se realiza sobre dos parámetros opcionales. Así, en ausencia de un argumento específico o si este no es un valor booleano, se establecerá automáticamente su valor como FALSO por defecto. Esto permite que la ejecución prosiga con normalidad sin generar ninguna excepción.
En general, pienso que es importante otorgarle a este tipo de controles sobre los argumentos de las funciones personalizadas la importancia que tienen. Al fin y al cabo, nuestro objetivo también es el de proporcionar a las personas que las van a utilizar una buena experiencia de usuario. Tratar de manera adecuada las situaciones de error cuando se producen también contribuye a lograrlo.
☝ A medida que las funciones se van haciendo más complejas, surgen nuevas situaciones que probablemente deban ser tenidas en cuenta en esta fase inicial de validación de parámetros. Ponte en la piel de quien va a utilizarlas, trata de "romperlas" de mil maneras para identificar así las verificaciones críticas y emitir los correspondientes mensajes de error, que por otra parte siempre deben ser claros y accionables.
Interpretación de los parámetros de selección
Realmente, el núcleo de esta función personalizada, su cerebro y motor, lo encontrarás en las líneas 58-136.
Se trata de una función auxiliar privada que se encarga del trabajo duro, es decir, de analizar los argumentos columnas y filas, que como hemos visto pueden construirse de diferentes maneras, para extraer de ellos sendos vectores que representarán los índices de las correspondientes filas y columnas seleccionadas que eventualmente se devolverán como resultado.
/**
* Función auxiliar para procesar los argumentos de selección de filas y columnas.
* Interpreta la lista de filas o columnas seleccionadas y devuelve
* un vector con los numeros naturales correspondientes.
* @param {Array.<number>|Array.<string>} vector
* @param {number} longitud
* @param {string} contexto Literal 'filas' o 'columnas' para tratamiento excepciones y análisis en modo encabezados.
* @return {Array.<number>}
*/
function interpretarVectorIndices(vector, longitud, contexto) {Esta función será invocada en dos ocasiones de el bloque [4] de la función, que veremos en unos minutos, y recibirá el argumento facilitado a HDCP_SUPERCHOOSECOLS que representa las columnas o filas a seleccionar (parámetro vector).
Como resultado, devolverá un vector de índices numéricos que permitirá al código del bloque [4] construir con facilidad la matriz de datos que a su vez se devolverá como resultado final de la función HDCP_CHOOSECOLSROWS.
Para realizar correctamente su trabajo, esta función auxiliar precisa conocer el número de filas y columnas del intervalo de datos del que se desea realizar la extracción (parámetro longitud) , así como si está operando sobre un vector que representa índices de filas o columnas. Esto se consigue gracias a su parámetro contexto.
Primeramente se determinará si:
- Se ha omitido el argumento para seleccionar columnas o filas (líneas 69 - 70). En ese caso se optará por seleccionar todas las columnas o filas de forma predeterminada. Es relevante señalar que cuando se omite un parámetro al llamar a la función saltando al siguiente mediante el uso de un punto y coma [
;], el valor que la función recibirá para ese parámetro será una cadena vacía. Esto difiere del valor indefinido (undefined) que se asigna cuando un parámetro no se llega a especificar ni saltar. - El argumento de selección es un vector de un solo elemento, por ejemplo {4}. En estos casos la función no recibirá un vector, sino un valor numérico único, que se convertirá en un vector de longitud 1 por uniformidad (líneas 72 - 73).
function interpretarVectorIndices(vector, longitud, contexto) {
// Si el argumento se ha omitido o es un valor único 0, seleccionar todas las filas/columnas
if (!vector) vector = [...Array(longitud).keys()].map(indice => indice + 1);
// ¡Si el argumento es un array de 1 solo elemento, CHOOSECOLSROWS recibirá un valor que no es de tipo array!
if (!vector.map) vector = [vector];
Y atención, porque llegamos a la parte importante en las líneas 75 - 134.
Aquí se aplana el vector de selección de elementos con el método Array.flat(), de modo que la cosa funcione sin problemas tanto si el usuario ha suministrado los índices (o expresiones de selección) en un vector fila:
{ 3 \ "5-14" \ ... }como en un vector columna:
{ 3 ; "5-14" ; ... }... y se recorren todos los elementos en su interior (línea 76) para analizarlos mediante un bucle reduce, que nos permitirá tomar decisiones de manera flexible sobre cada uno de ellos, al tiempo que se va construyendo el vector de índices a devolver sobre la variable resultado.
Es de esperar que este vector de índices de fila o columna contenga un número de valores superior al de elementos de selección facilitados en el parámetro vector. Esto es así puesto que probablemente alguno de estos últimos sea una expresión alfanumérica que designe un intervalo de filas o columnas, en lugar de una fila o columna única.
// Se usa flat() para admitir tanto vectores filas {\} como columna {;} como lista de índices de fila/columna
return vector.flat().reduce((resultado, indice) => {
if (typeof indice == 'number') {
// ### El selector de fila/columna es un valor numérico positivo o negativo ###
indice = Math.trunc(indice); // Soporte para índices no enteros (los decimales se ignoran)
if(Math.abs(indice) > longitud) throw `Índice ${indice} fuera de rango en argumento «${contexto}»`;
// Índices negativos suponen comenzar a contar desde la última fila o columna del intervalo
else return resultado.concat(indice < 0 ? longitud + indice + 1 : indice);
} else if (typeof indice == 'string' && ((contexto == 'columnas' && !usa_etiquetas_col) || (contexto == 'filas' && !usa_etiquetas_fil))) {
// ### El selector de fila/columna es una expresión de texto que indica un intervalo de filas/columnas ###
let [inicio, fin] = indice.split('-');
// Sustituir por primera o última fil/col en caso de intervalos abiertos (ej; "-4" o "5-")
inicio = Math.trunc(Number(!inicio ? 1 : inicio));
fin = Math.trunc(Number(!fin ? longitud : fin));
// Corrección en el caso de índices cruzados (ej: "4-1"), opto por desactivarla dado que ocasiones produce mensajes de error confusos cuando
// solo se indica un índice de fila o columna superior a la longitud, dado que pasa a ser interpretado como índice final al ser intercambiado por
// el valor del índice máximo. En su lugar lanzo excepción cuando los índices están cruzados.
// [inicio, fin] = [Math.min(inicio, fin), Math.max(inicio, fin)];
// Excepción si no han podido determinarse índices numéricos a apartir de la expresión del selector de fila/columna
if(Number.isNaN(inicio)) throw `El índice inicial en la expresión de intervalo "${indice}" del argumento «${contexto}» no es válido`;
if(Number.isNaN(fin)) throw `El índice final en la expresión de intervalo "${indice}" del argumento «${contexto}» no es válido`;
// Excepción si índices fuera de rango
if (inicio < 1 || inicio > longitud) throw `Índice inicial ${inicio} fuera de rango en la expresión de intervalo "${indice}" del argumento «${contexto}»`;
if (fin < 1 || fin > longitud) throw `Índice final ${fin} fuera de rango en la expresión de intervalo "${indice}" del argumento «${contexto}»`;
if (inicio > fin) throw `El índice final ${fin} es anterior al inicial ${inicio} en la expresión de intervalo "${indice}" del argumento «${contexto}»`;
// Devolver secuencia de índices consecutivos entre inicio y fin
return resultado.concat([...Array(fin - inicio + 1).keys()].map(indiceIntervalo => inicio + indiceIntervalo));
} else if (typeof indice == 'string' && contexto == 'columnas' && usa_etiquetas_col) {
// ### El selector de columna es una cadena de texto que coincide con alguna de las etiquetas en la fila de encabezado ###
// Identificar la posición de la columna cuyo texto de encabezado es coincidente con el valor de la variable "indice"
const indiceColumna = intervalo[0].indexOf(indice);
if (indiceColumna == -1) throw `La etiqueta de encabezado de columna «${indice}» no se encuentra en la primera fila del intervalo`;
else return resultado.concat(indiceColumna + 1);
} else if (typeof indice == 'string' && contexto == 'filas' && usa_etiquetas_fil) {
// ### El selector de fila es una cadena de texto que coincide con alguna de las etiquetas en la columna de encabezado ###
// Identificar la posición de la fila cuyo texto de encabezado es coincidente con el valor de la variable "indice"
const indiceFila = intervalo.map(fila => fila[0]).indexOf(indice);
if (indiceFila == -1) throw `La etiqueta de encabezado de fila «${indice}» no se encuentra en la primera columna del intervalo`;
else return resultado.concat(indiceFila + 1);
} else throw `Error inesperado, revisa el argumento «${contexto}»`;
}, []);
}
Esta sección contempla las cuatro situaciones con las que nos podemos encontrar a la hora de analizar cada uno de los elementos de selección de filas o columnas contenidos en la variable vector:
- El elemento de selección es un índice numérico de fila o columna (líneas 78 - 85). Se eliminan por medio de Math.trunc() los posibles dígitos de su parte decimal (de este modo la función se hace resistente a los errores que podrían causar índices no enteros) y se comprueba que el índice esté comprendido dentro del rango de filas o columnas del intervalo de datos. Si el índice es negativo se interpretará desde el extremo derecho del intervalo, cuando se seleccionan columnas, o inferior, al seccionar filas. En caso contrario, la función finalizará con error de modo análogo al descrito cuando hablábamos del control de parámetros, emitiendo también un mensaje significativo para el usuario.
- El elemento de selección es una cadena de texto que designa un intervalo de filas o columnas, algo como "columna1-columna2" (líneas 87 - 112). En este caso, se extraen los índices de inicio y fin de la expresión de texto y se verifica que se trate realmente de valores numéricos válidos. Se consideran los intervalos abiertos, tales como "-5" o "10-", y se generan y devuelven los vectores de índices correspondientes.
- El elemento de selección es una cadena de texto que coincide con una etiqueta en la fila de encabezado del intervalo de datos (líneas 114 - 121). Se coteja la etiqueta con las que se hallan en la fila de encabezado y se obtiene el índice de la columna en la que se produce la coincidencia. De no encontrarse, ya sabes, excepción informativa y fin de la ejecución.
- El elemento de selección es una cadena de texto que coincide con una etiqueta en la columna de encabezado del intervalo de datos (líneas 123 - 130). Análogo al anterior, pero cuando se trata de seleccionar filas.
Finalmente, y simplemente por prudencia, se emite un mensaje de error genérico en cualquier otra circunstancia.
Generación del resultado y control de errores
Realmente, llegados a este punto (líneas 138 - 160) ya está todo el pescado vendido y solo nos queda recoger el fruto del trabajo realizado en los bloques de código previos. ¡Qué reconfortante!
try {
// Interpretar argumentos de selección de filas y columnas
const filasSeleccionadas = interpretarVectorIndices(filas, intervalo.length, 'filas')
const columnasSeleccionadas = interpretarVectorIndices(columnas, intervalo[0].length, 'columnas');
// Devolver matriz de datos con las filas y columnas seleccionadas
return filasSeleccionadas
// Filetear filas
.reduce((matrizReducida, fila) => matrizReducida.concat([intervalo[fila - 1]]), [])
// Filetear columnas
.map(fila => columnasSeleccionadas.reduce((filaReducida, columna) => filaReducida.concat(fila[columna - 1]), []));
} catch (e) {
throw typeof e == 'string'
? e
: `Puede que hayas combinado los símbolos ";" y "\\" de manera inapropiada
en los argumentos de selección de columnas o filas {...} o
usado una expresión no admitida para escogerlas.
Información de diagnóstico: "${e}"`;
}
}
Primero, en las (líneas 140 - 142) se llama en dos ocasiones a la función auxiliar que acabamos de analizar para construir los vectores de índices de filas y columnas seleccionadas.
A continuación (líneas 144 - 149), se monta y devuelve el intervalo de datos resultante a partir de esos vectores de índices.
Y otra vez por precaución, esta sección del código está presidida por un bloque try ... catch, cuya misión es permitirnos "fallar graciosamente" en aquellos casos en los que los controles previos —que no han sido pocos— no hayan podido cazar alguna situación susceptible de provocar un error en tiempo de ejecución.
En ese caso se emitirá un nuevo mensaje de error genérico y se facilitará información adicional para tratar de diagnosticar el problema (líneas 151 - 158).
¡Listo! Breve, pero con cierta intensidad, ¿verdad 😏?
¿Mejoras?
Claro. ¡Siempre las hay.
Pienso que sería beneficioso implementar en el mecanismo de selección de etiquetas de encabezado la capacidad de aceptar caracteres comodín. No sería necesario algo demasiado complicado; el uso del asterisco [*] para sustituir una secuencia de caracteres y posiblemente el signo de interrogación [?] para reemplazar un solo carácter serían suficientes. Esta mejora abriría la puerta a nuevos escenarios de uso más versátiles, permitiendo, por ejemplo, elegir todas las columnas que compartan un prefijo o sufijo específico en sus etiquetas de encabezado.
¡Me has leído la mente! Estoy pensando en las preguntas de tipo cuadrícula de casillas o varias opciones de los formularios de Google, en las que el título de la pregunta se añade como prefijo al texto de cada fila o dimensión al volcar las respuestas en una hoja de cálculo.
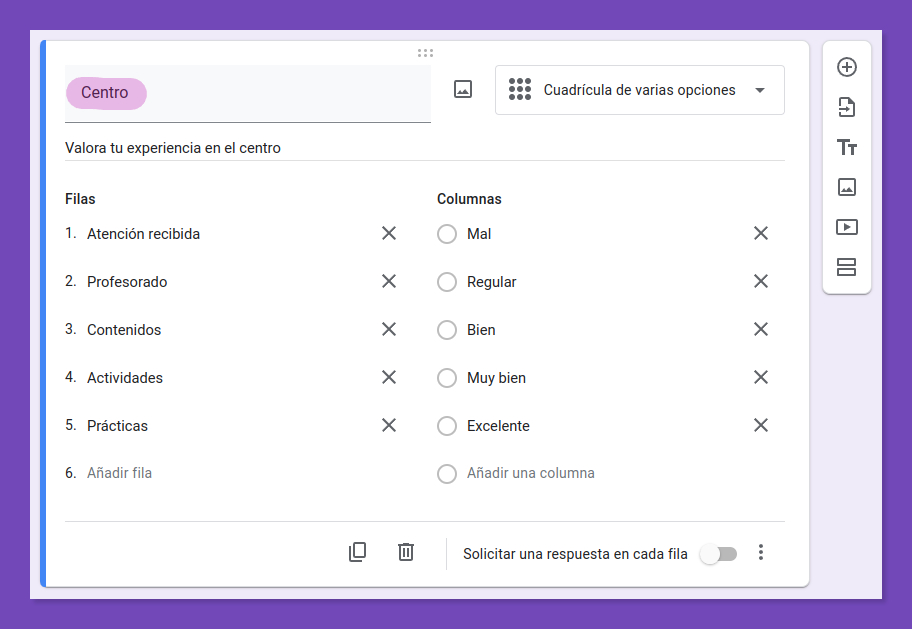
Sería necesario desarrollar una estrategia efectiva para manejar la aparición de dichos caracteres comodín en las etiquetas de encabezado, por supuesto. Y, si es factible, lograr esto sin alterar la sintaxis existente de la función.
Es cierto que esta funcionalidad se puede emular con cierta facilidad utilizando la función nativa de las hojas de cálculo FILTER, pero en cualquier caso me parece un problema interesante, cuya resolución pasa seguramente por el uso intensivo de expresiones regulares, que tal vez en algún momento aborde 🤔.
Otra modificación, en cierta manera relacionada con la anterior, consistiría en eliminar los argumentos de tipo booleano usa_etiquetas_col y usa_etiquetas_fil. Esto implicaría que la función personalizada pudiera decidir por sí misma si un selector de columna o fila alfanumérico es una etiqueta de encabezado, como "Edad", o una expresión de intervalo, como "5-20". De este modo, ambos tipos de selectores podrían también combinarse en las expresiones matriciales de los argumentos columnas y filas, algo que la función no admite actualmente.
¿Qué te parece? ¿Se te ocurre alguna idea feliz para implementar estas mejoras? ¡No dejes de contármela en la caja de comentarios más abajo 💬👇!
Comentarios finales
En esta hoja de cálculo encontrarás el código de las dos funciones que hemos desarrollado paso a paso, SUPERCHOOSECOLS y HDCP_CHOOSECOLSROWS, así como el de una versión intermedia a medio camino entre ambas de la que no hemos hablado, además de varios ejemplos de uso para las tres.
Si este tinglado te parece útil, me permito sugerirte que pruebes mi complemento HdC+ para Google Sheets. Es totalmente gratuito, sin registro de ningún tipo, y de código abierto. Además de la versión más avanzada de las funciones personalizadas de las que hemos hablado hoy, incluye muchas otras funciones y herramientas, permanentemente actualizadas, para hacerte la vida más fácil cuando trabajes con las hojas de cálculo de Google.
La última versión (1.8) está calentita... y ya tengo en el horno la versión 1.9 con más utilidades hojacalcúlicas 🤓.
📣 Nueva versión de #HdCPlus, mi complemento para #GoogleSheets.
— Pablo Felip (@pfelipm) January 20, 2024
👀 https://t.co/MsDlYkfC3A
📥 https://t.co/ullg8ixJVe
Hilo rápido con las novedades ⤵️ pic.twitter.com/FyQNLSloLG
También puedes visitarme en tictools.tk para conocer más sobre las funcionalidades de HdC+ y otros artefactos Apps Script que comparto.
Gracias por acompañarme una vez más 👋.
Comentarios