En este artículo se hace un recorrido por las distintas técnicas disponibles en Data Studio para construir informes diferenciados por usuario, típicamente basados en filtros de datos aplicados sobre la dirección de correo de la persona que los consume, y se presenta un modo seguro de filtrar un conjunto de datos usando una lista de direcciones separadas por comas y la función integrada DS_USER_EMAIL().
Si sigues mis publicaciones, probablemente sepas que Google Data Studio es una de mis obsesiones. Se trata de una herramienta por cuyo uso he venido abogando con insistencia desde hace años, cuando aún era una gran desconocida en el ámbito educativo, tanto en este espacio como en mis redes sociales, así como en diversos encuentros de desarrollo profesional (IBTAC 2018, GEG Valencia 2019), cursos, etc.
Hablando sobre Data Studio en la vieja comunidad de GEG Spain en Google+. ¡Ah, qué tiempos!
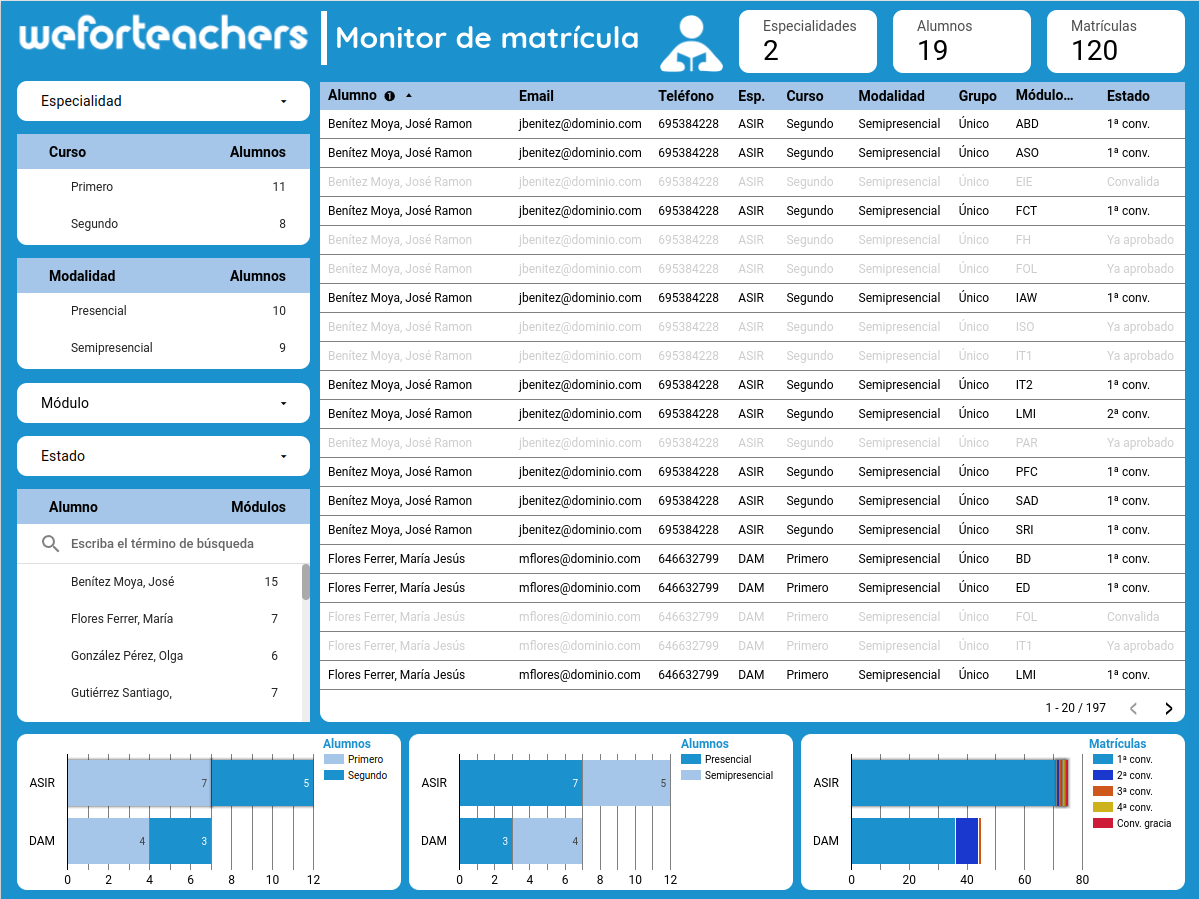
Una de las cosas que siempre me ha interesado particularmente de Data Studio ha sido la posibilidad de crear informes (o paneles de mando, que no son exactamente la misma cosa) con vistas personalizadas por usuario, de modo que cada lector del informe solo pueda visualizar una parte del conjunto de datos original: Un solo informe que proporciona información diferenciada para múltiples consumidores con intereses específicos.
Piensa en cosas como resultados académicos, sesiones de Google Meet, partes de trabajo abiertos, alumnado matriculado en distintas asignaturas... todo segmentado de manera que cada persona que accede al informe tenga acceso solo a la información que le resulta relevante o para cuyo acceso dispone de autorización.
Un ejemplo de panel de mando Data Studio que funciona como monitor de matriculación.
Se trata, en esencia, de transformar los informes de Data Studio en pequeñas aplicaciones web dinámicas, que pueden construirse con mínimo coste y sin necesidad de disponer de conocimientos especializados de programación, para servir información de manera unidireccional, diferenciada por usuario.
Soluciones basadas en la parametrización de URL
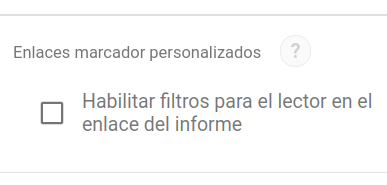
Las primeras estrategias que recuerdo estaban basadas en el uso de URL personalizados gracias a una característica de Data Studio, desactivada por defecto sin embargo en cualquier informe, denominada enlaces marcador personalizados.
Gracias a estos enlaces personalizados es posible generar fácilmente, por ejemplo mediante fórmulas en una hoja de cálculo, distintos URL en los que se inserta un parámetro de consulta con el que se establecen diferentes valores predefinidos para los controles de filtro interactivos presentes en el informe.
Al acceder a un informe usando uno de estos enlaces especiales se mostrarán solo los datos deseados como consecuencia de la aplicación del filtro establecido que se ha codificado en el URL, por ejemplo los correspondientes a un registro específico de una tabla determinada.
Pero si lo que perseguimos no es solo conveniencia sino cierta privacidad, tendremos que bloquear los controles de filtro interactivos para que el usuario no pueda modificarlos manualmente, accediendo así a información potencialmente no autorizada. Esto puede resolverse de manera trivial superponiendo sobre los controles de filtro formas transparentes o llevándolos fuera del área visible del informe
Por otro lado, además, es aconsejable ofuscar los valores utilizados en el parámetro de consulta de la URL para al menos paliar así en la medida de lo posible ataques de adivinación de URL.
Como podrás comprobar en este este interesante artículo de Stéphane Hamel, la cosa tiene cierta complejidad, además de resultar aparatosa y frágil, dado que todo depende de la sintaxis de la cadena de consulta de los URL que se construyen. De hecho, aunque el artículo ya tiene unos años, el autor se ha visto obligado a modificarlo más recientemente puesto que el parámetro utilizado por Data Studio para representar la definición de estos filtros en los URL pasó en algún momento (tal vez con la introducción de los parámetros en Data Studio) de llamarse config a param, rompiendo cualquier informe existente, claro está.
Además, la seguridad —bastante laxa, no cabe duda— debe conseguirse facilitando a través de algún canal esos URL personalizados a las personas adecuadas, sin que exista garantía alguna de su confidencialidad.
Filtro por dirección de correo electrónico
En febrero de 2020 el "estado del arte" dio un paso de gigante con la introducción de la seguridad a nivel de registro por medio del filtrado por dirección de correo electrónico.
La función de filtrado basado en la dirección de correo electrónico de Data Studio, en acción.
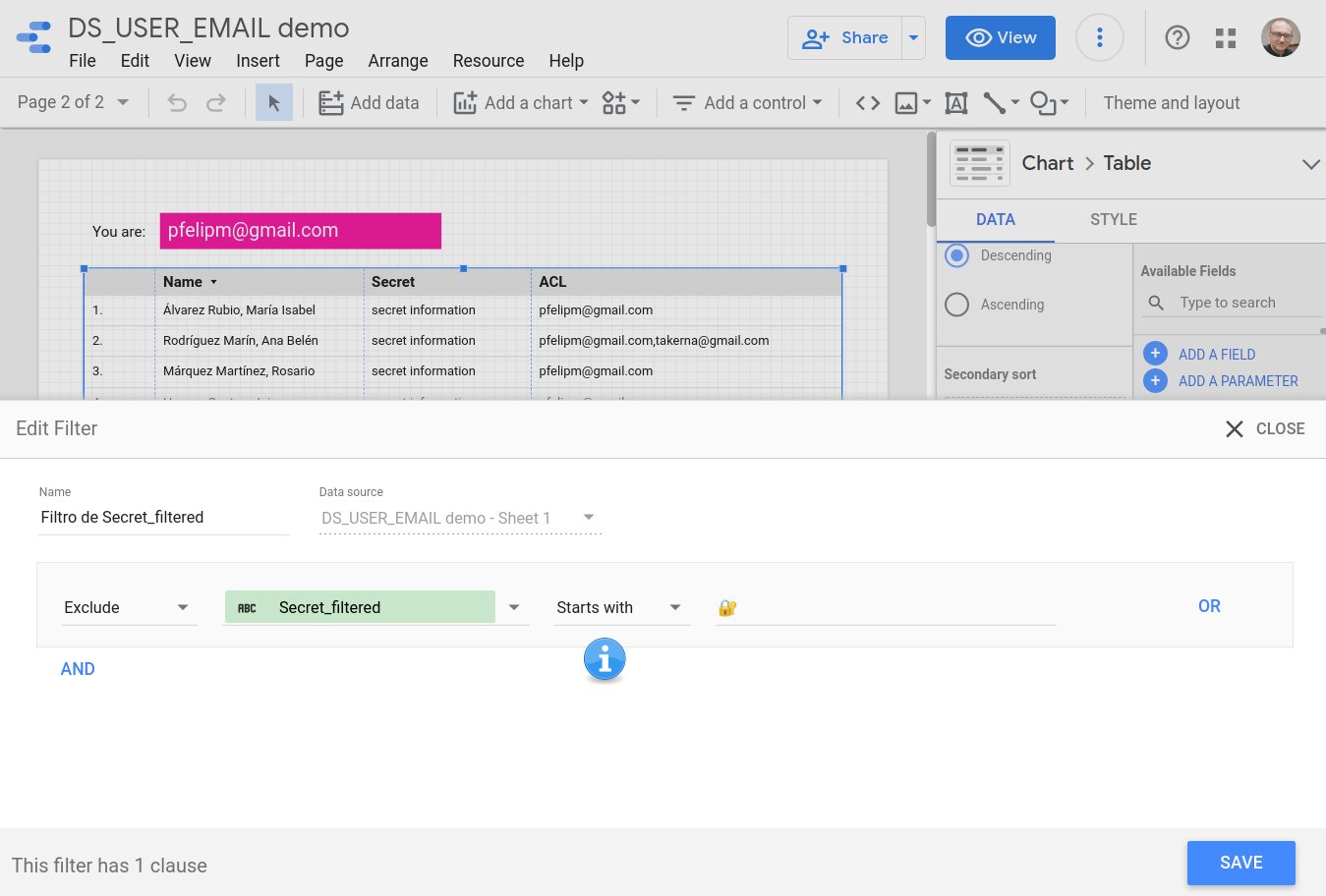
De repente, cualquier informe Data Studio podía diseñarse de modo que se utilizara la cuenta de Google del usuario que accedía al informe, siempre que lo hiciera habiendo iniciado previamente sesión en ella, para mostrarle así solo aquellos registros facilitados por una fuente de datos en los que un campo determinado contuviera una dirección de correo electrónico coincidente.
Uno de los primeros artículos en este espacio iba precisamente de cómo utilizar las combinaciones de datos junto con el filtro por dirección de correo para crear grupos de seguridad compuestos por múltiples conjuntos de usuarios con idénticos permisos de acceso a los datos. Tal vez quieras echarle un vistazo, puesto que sigue siendo el modo oficial de aplicar políticas da seguridad basadas en la dirección de correo electrónico a un conjunto de usuarios.
Otra estrategia, más potente y flexible a la hora de filtrar los datos en función de la identidad de la persona que visualiza el informe, aunque al mismo tiempo seguramente más alejada del usuario final característico de Data Studio, pasa por la creación de conectores de datoscomunitarios ad hoc, algo que se consigue usando Google Apps Script.
Trabajando en esta línea, en agosto del 2021 publicaba este artículo, quizás el más extenso y exhaustivo que he escrito hasta el momento, en el que abordaba nuevamente la problemática del control de acceso basado en el email de la persona que acceder al informe, aunque en ese momento desde la perspectiva del diseño de conectores comunitarios y bien pertrechado de todas las armas que Apps Script ofrece para interactuar con los conjuntos de datos almacenados en los servicios de Google Workspace antes de que alcancen la capa de representación de Data Studio.
Y fue precisamente mientras andaba liado preparando este artículo que la cosa dio un nuevo vuelco.
La función DS_USER_EMAIL()
De manera inesperada, sin anuncio oficial de ningún tipo, en agosto de 2021 descubrimos que el lenguaje de fórmulas de Data Studio admitía una nueva y sorprendente función denominada DS_USER_EMAIL(). De hecho, aún hoy en día no se encuentra mención alguna a ella en la documentación de Data Studio, en la que solo se habla del parámetro @DS_USER_EMAIL, algo exclusivo de las fuentes de datos basadas en BigQuery, pero que esencialmente sirve al mismo propósito.
De repente, gracias a DS_USER_EMAIL(), y también a ciertas mejoras oportunas introducidas durante ese mismo mes de agosto en la sintaxis de las fórmulas de Data Studio, era posible construir campos calculados con fórmulas que usaran las funciones de análisis y manipulación de cadenas de texto para cotejar la dirección de correo del lector del informe con los valores contenidos en uno o más campos de un conjunto de datos.
Esos campos calculados, junto con el uso apropiado de filtros a nivel del informe, página o control, abrieron la puerta a cosas enormemente interesantes, y sin código, como por ejemplo (tiro de tuiteroteca para no extenderme demasiado):
Row-level security using a comma-separated ACL field in #DataStudio for a #GoogleSheets data source *without* filter by email enabled using DS_USER_EMAIL parameter (same as with #BigQuery ‼️) ✌️ @mim_djo @tiltondata @SumifiedHQ
*Full* row-level security matching 👀📨 with a comma-separated list of addresses / row using DS_USER_EMAIL() in non-#BigQuery data sources! #DataStudio. Now uses a calc. field to tag records that shouldn't be displayed for the current viewer and report/page/chart level *filters*.
📢 #DataStudio release notes 🗓️ Aug 19th: Useful functions for text matching now support fields and expressions + we also get 🆕 REGEXP_CONTAINS()! Enter row-level security by viewer domain (or all *) 🌐📨 using DS_USER_EMAIL(), calc. fields and filters (official announcement).
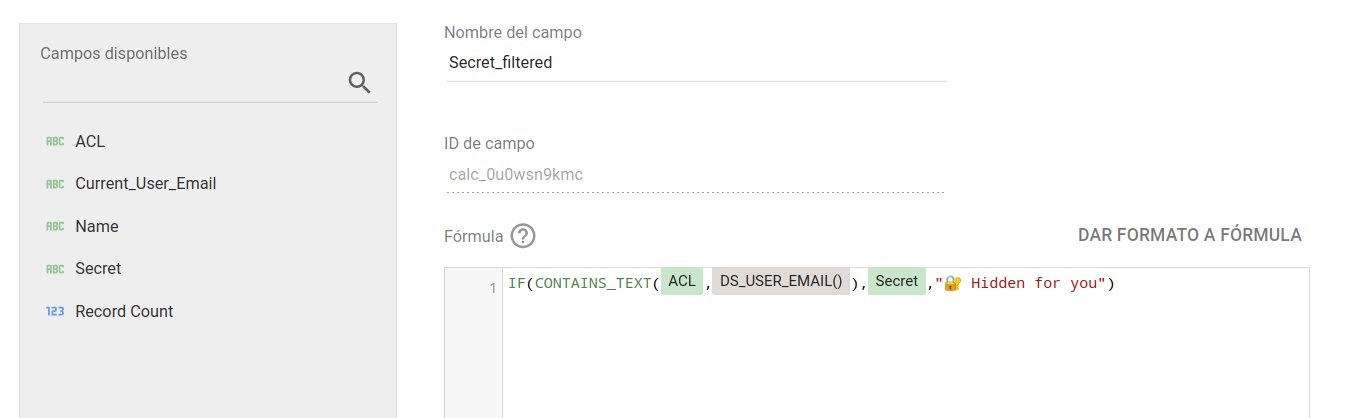
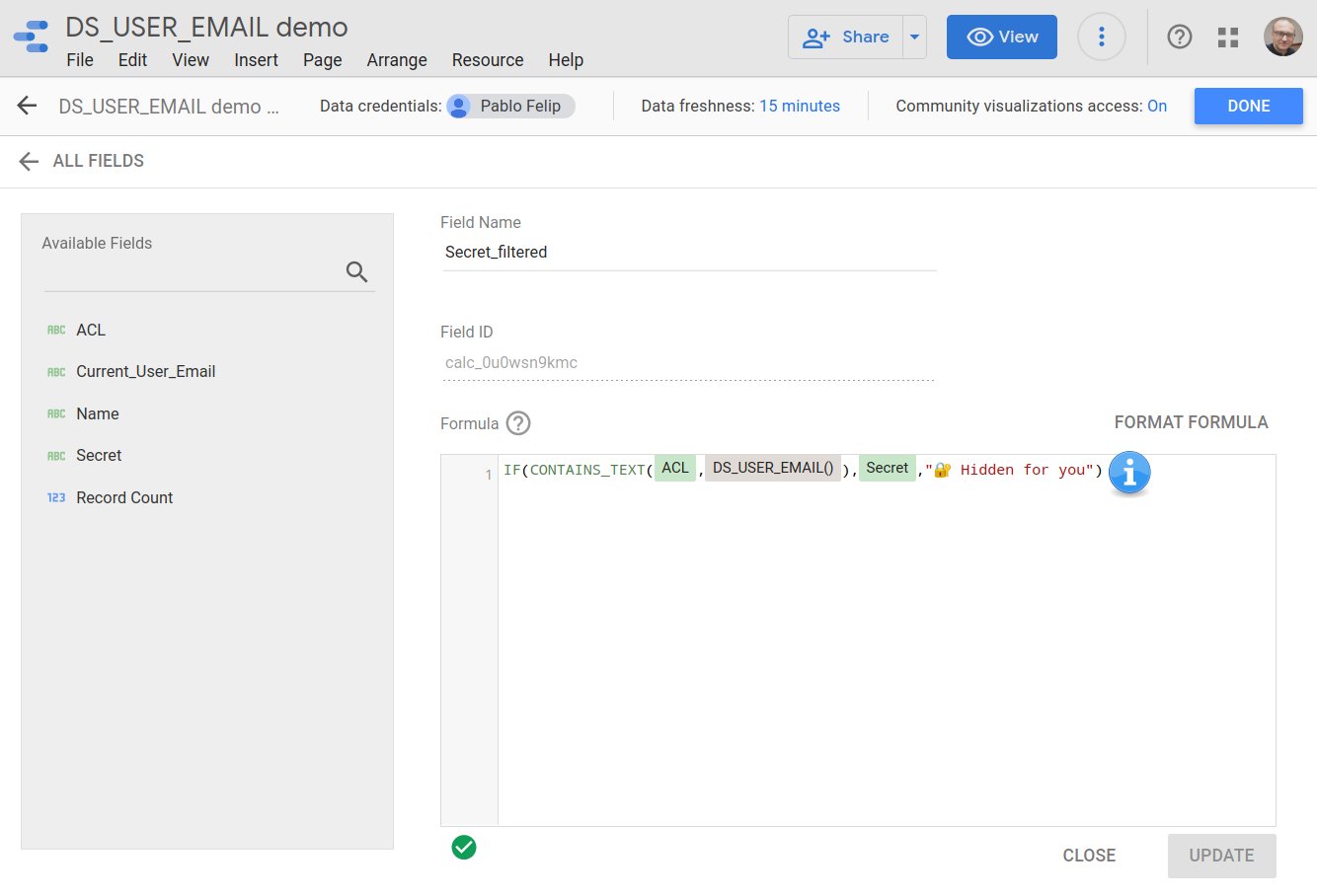
Las tres pruebas de concepto anteriores se basan en el uso de la funciónCONTAINS_TEXT() en un campo calculado para determinar si el valor devuelto por DS_USER_EMAIL()aparece en la lista de direcciones de correo o dominios autorizados, separados por comas, y visualizar (o no) cada registro, por ejemplo:
El resultado de la expresión anterior será un valor verdadero (true) o falso (false), que se utilizará en un filtro de informe, página o control para mostrar solo aquellos registros del conjunto de datos que hayan superado la comprobación.
El procedimiento es simple y aparentemente efectivo, pero esconde no obstante un inconveniente importante.
Una aproximación segura a la segmentación mediante listas de direcciones
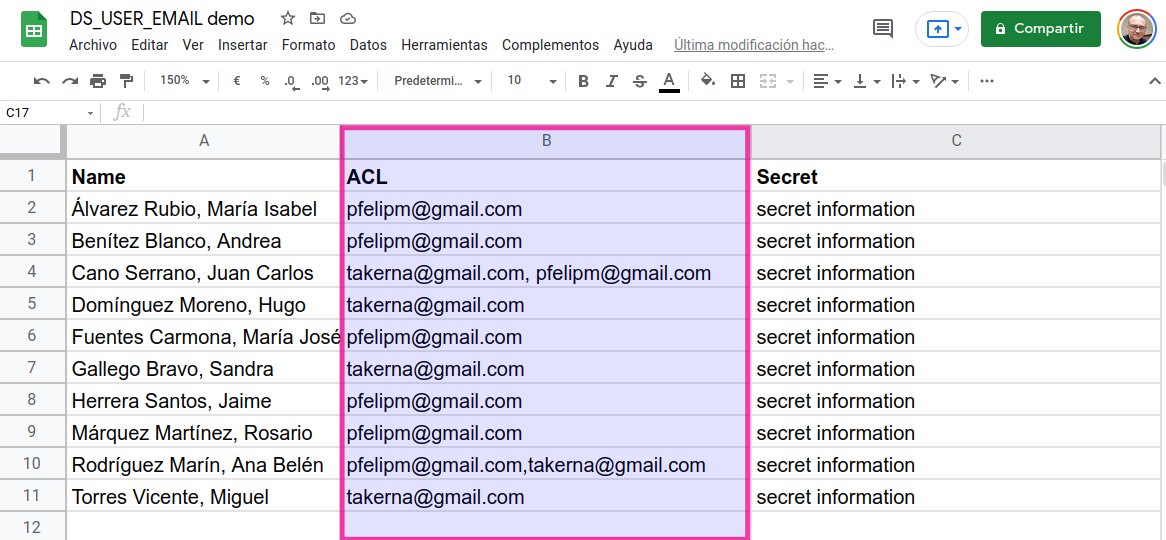
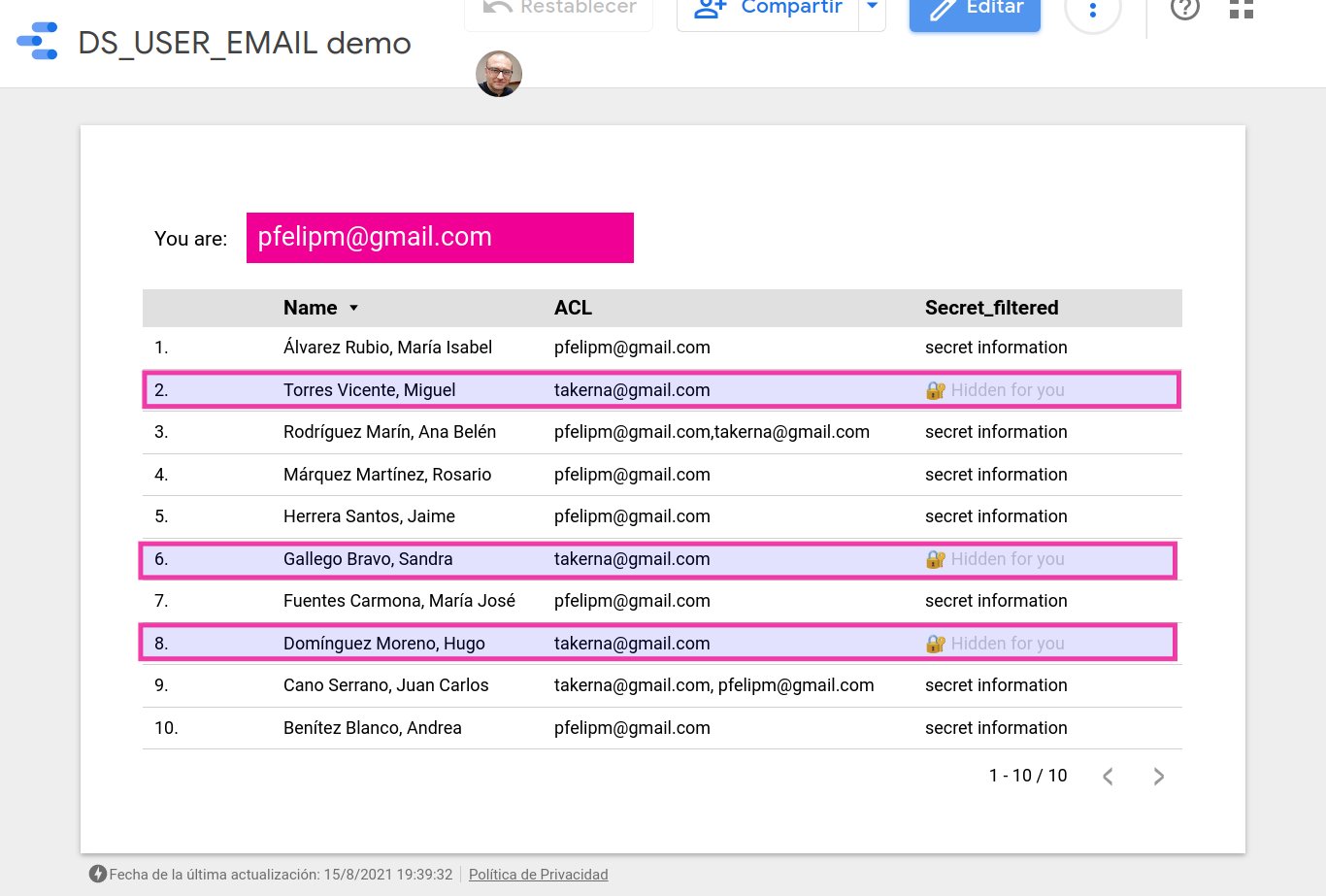
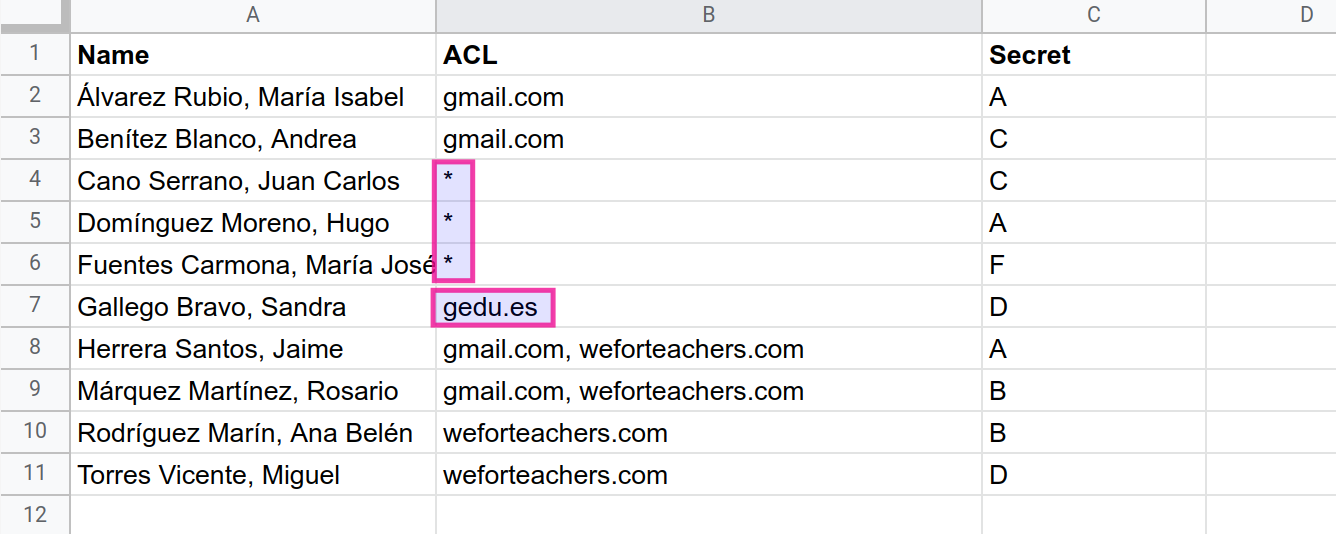
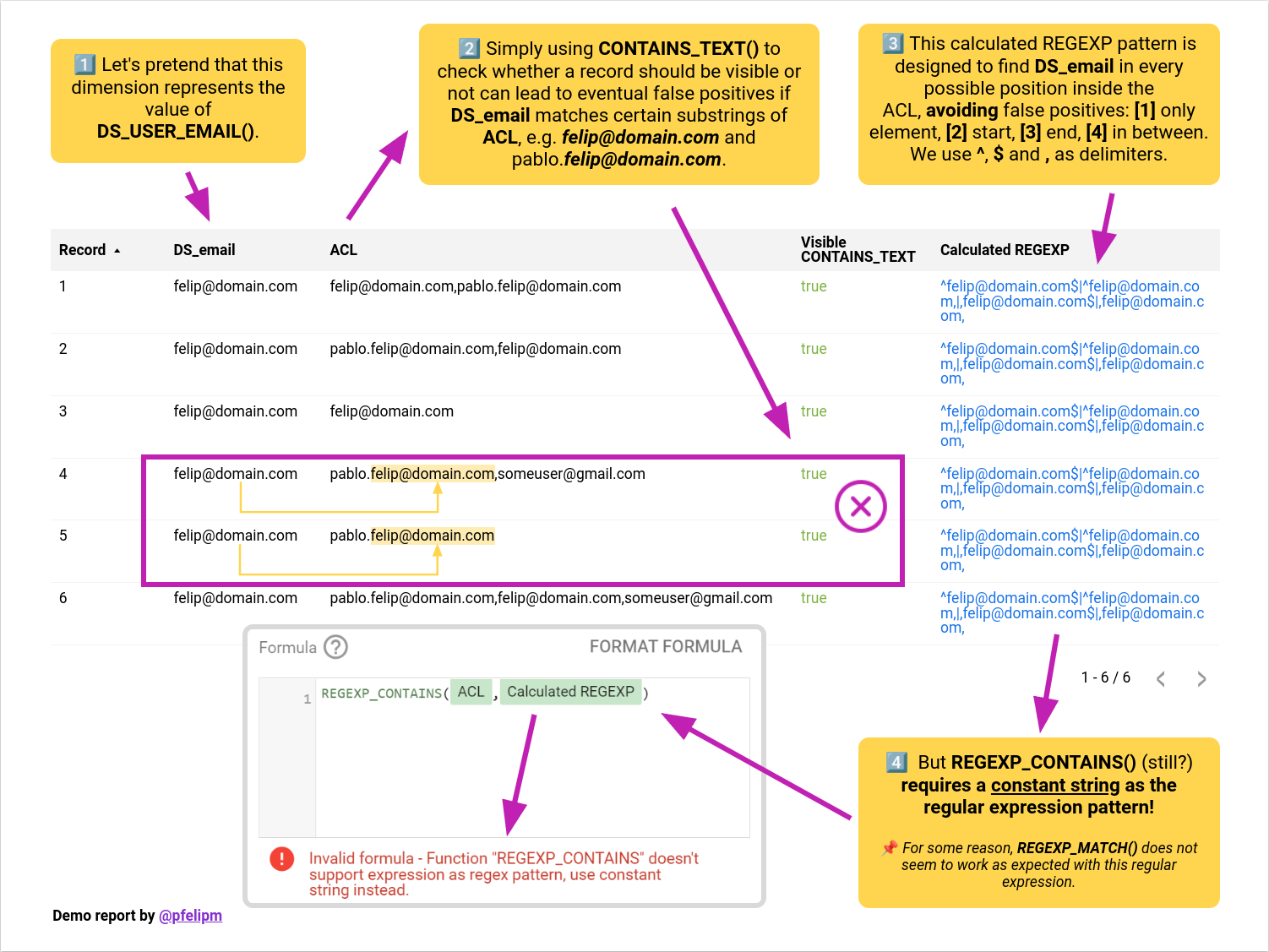
Para apreciar la deficiencia de la estrategia descrita en el apartado anterior, supongamos que en uno de los registros de nuestro conjunto de datos nos encontramos con una lista de control de acceso como esta:
pablo.felip@domain.com,someuser@gmail.com
Si la dirección de correo electrónico de la persona que accede al informe es, por ejemplo felip@domain.com, esta estrategia fallará inmediamente, dado que CONTAINST_TEXT() devolverá un valor verdadero, al hallarse la dirección de correo del usuario formando parte de la secuencia de texto «pablo.felip@domain.com».
¿Constituye esto un problema? Evidentemente, aunque tal vez de impacto limitado si se conocieran de antemano las identidades de las personas con acceso potencial al informe (por ejemplo, por estar restringida su visibilidad a un dominio o grupo de usuarios específico) y los posibles casos de solapamiento de cadenas de texto en sus direcciones de correo electrónico pudieran ser identificados y, en su caso, descartados de manera temprana.
⚠️ Por tanto, la solución propuesta es aceptable solo con reservas y en cualquier caso dista mucho de poder aplicarse con carácter general.
Afortunadamente, es posible mejorar la estrategia de comprobación, si bien a costa de complicar un poco las cosas.
Data Studio cuenta entre su repertorio de funciones con una denominadaREGEXP_CONTAINS(), que permite cotejar una cadena de texto contra una expresión regular, en esencia un artefacto que describe un patrón de caracteres.
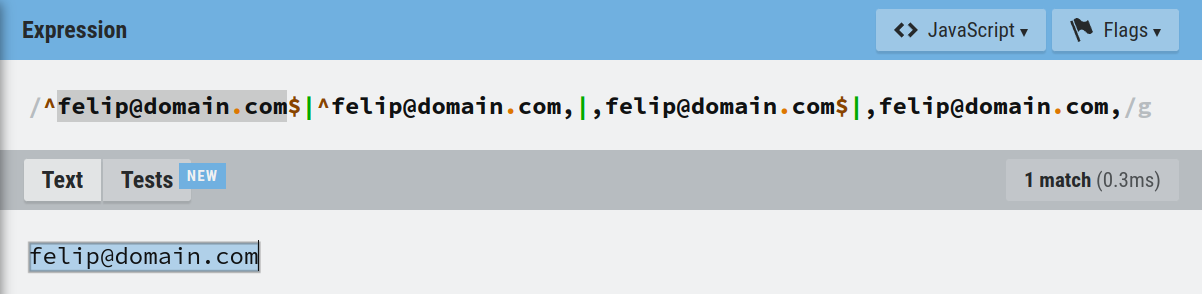
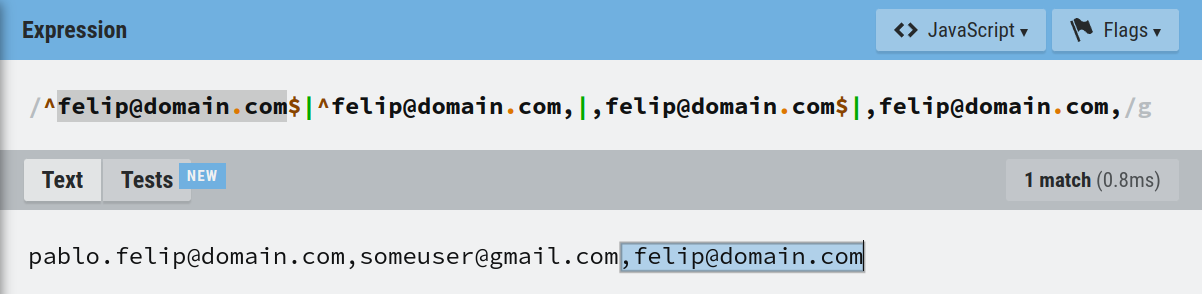
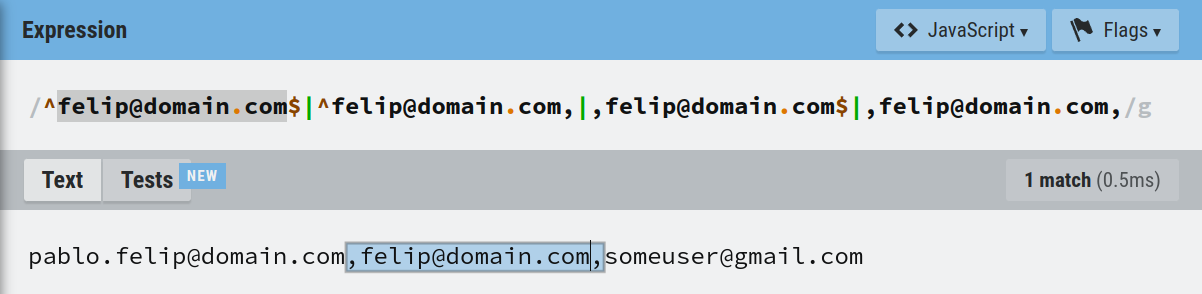
Una dirección de correo puede aparecer de cuatro maneras distintas dentro de una lista de control de acceso formada por direcciones separadas por comas:
1️⃣ Como dirección única. 2️⃣ En la primera posición de una lista con al menos dos direcciones. 3️⃣ En la última posición de una lista con al menos dos direcciones. 4️⃣ En una posición intermedia entre la primera y última dirección de la lista.
Resulta inmediato construir en un campo calculado, por concatenación de elementos, una expresión regular a partir de la cadena de texto devuelta por DS_USER_EMAIL() que permita comprobar la presencia de la dirección de correo de la persona que accede al informe de manera unívoca en cualquiera de los cuatro casos anteriores:
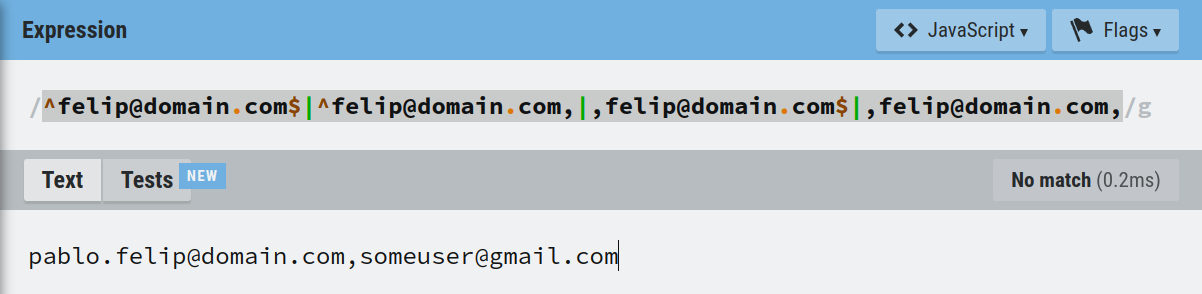
Se comprueba que la expresión regular propuesta es eficaz a la hora de detectar una dirección de correo electrónico dada que aparezca en cualquier posición de la lista de control de acceso, sin falsos positivos provocados por eventuales coincidencias parciales con determinadas secuencias de caracteres de las direcciones de correo de la lista.
Hay un problema, sin embargo: La expresión regular, construida al vuelo concatenando ciertos elementos de texto con el valor devuelto en cada momento y para cada usuario por DS_USER_EMAIL(), debería ser evaluada sobre la lista de control de acceso utilizando la funciónREGEXP_CONTAINS() de Data Studio. Pero, desgraciadamente, esta función solo admite en el momento presente expresiones regulares que sean cadenas de texto invariantes, no pudiendo usar como parámetro una expresión o un campo calculado en su lugar para construirlas de manera dinámica.
La siguiente infografía resume la situación:
No podemos usar REGEXP_CONTAINS() para cotejar DS_USER_EMAIL() con las direcciones de la lista de control de acceso.
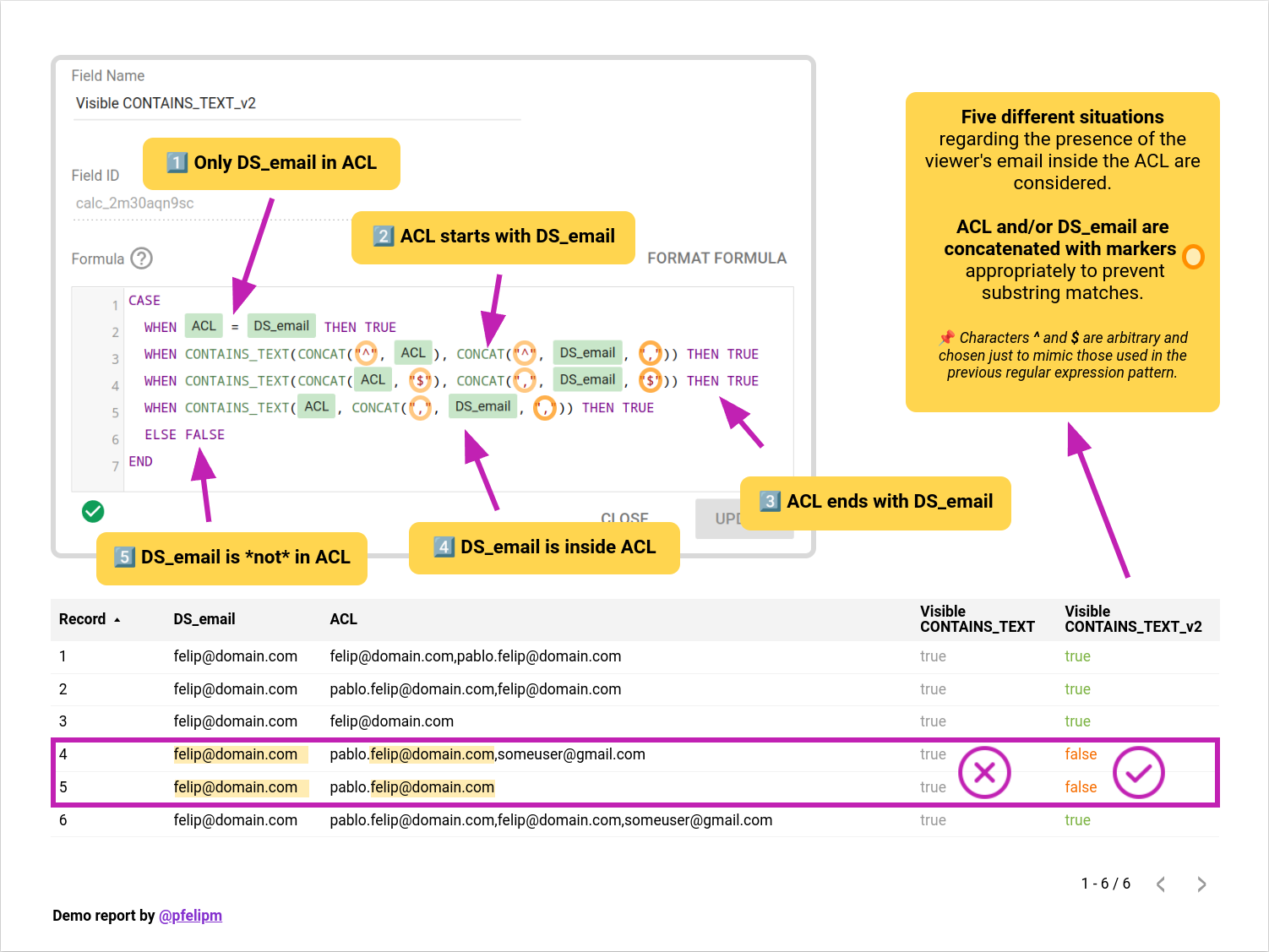
Afortunadamente, es posible transformar el problema de modo que pueda ser resuelto utilizando una expresiónCASE en su modalidad no simplificada, utilizando así en su lugar la función CONTAINS_TEXT() para determinar si la dirección de correo del usuario aparece, de alguno los cuatro modos posibles que ya conocemos, en la lista de direcciones separadas por comas. Hay que tomar no obstante ciertas precauciones que permitan evitar los falsos positivos.
💡 La idea feliz consiste en concatenar ciertos marcadores de posición con la lista blanca de control de acceso y la propia dirección de correo electrónico antes de compararlas. Estos marcadores son caracteres arbitrarios (aunque no deben aparecer formando parte de una dirección de correo en ningún caso) que actuarán como elementos delimitadores.
En este caso se ha optado por utilizar los mismos que señalizan el inicio (^) y final de la cadena de texto ($) en una expresión regular, simplemente por uniformidad.
De este modo, la secuencia de comprobación a seguir es la siguiente:
Caso 1️⃣:
CASE WHEN ACL = DS_email THEN TRUE
Caso 2️⃣:
WHEN CONTAINS_TEXT(CONCAT("^", ACL), CONCAT("^", DS_email, ",")) THEN TRUE
Caso 3️⃣:
WHEN CONTAINS_TEXT(CONCAT(ACL, "$"), CONCAT(",", DS_email, "$")) THEN TRUE
Caso 4️⃣:
WHEN CONTAINS_TEXT(ACL, CONCAT(",", DS_email, ",")) THEN TRUE
Si no se cumple ninguna de las condiciones anteriores, la expresión CASE devolverá finalmente un valor falso, indicando que la dirección de email no aparece en la lista de control de acceso para un registro dado y haciendo por tanto que el filtro aplicado sobre el informe, página o control lo omita.
ELSE FALSE END
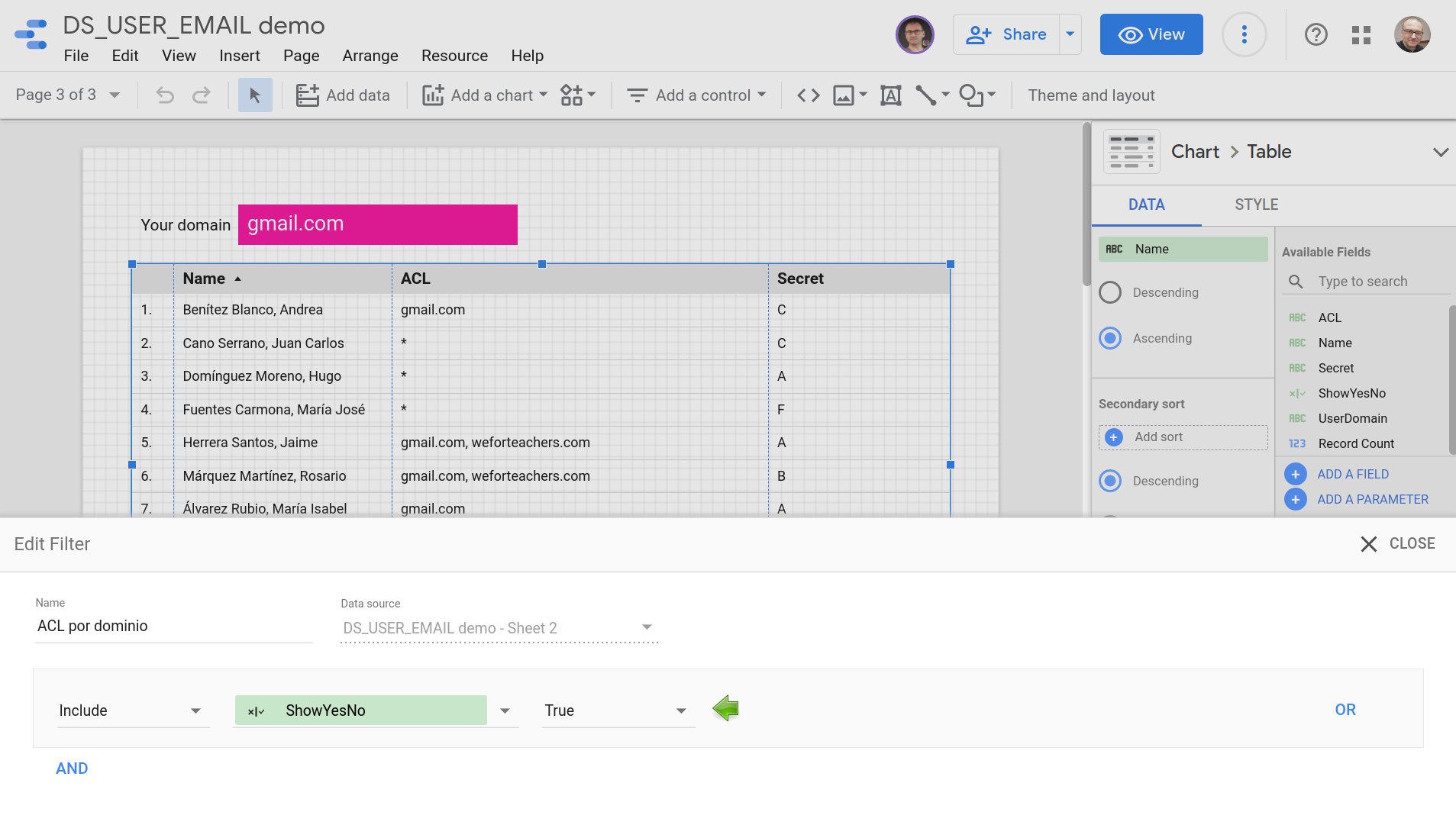
Esta segunda infografía resume la nueva estrategia.
Análisis por casos del problema y solución propuesta mediante CASE y CONTAINS_TEXT().
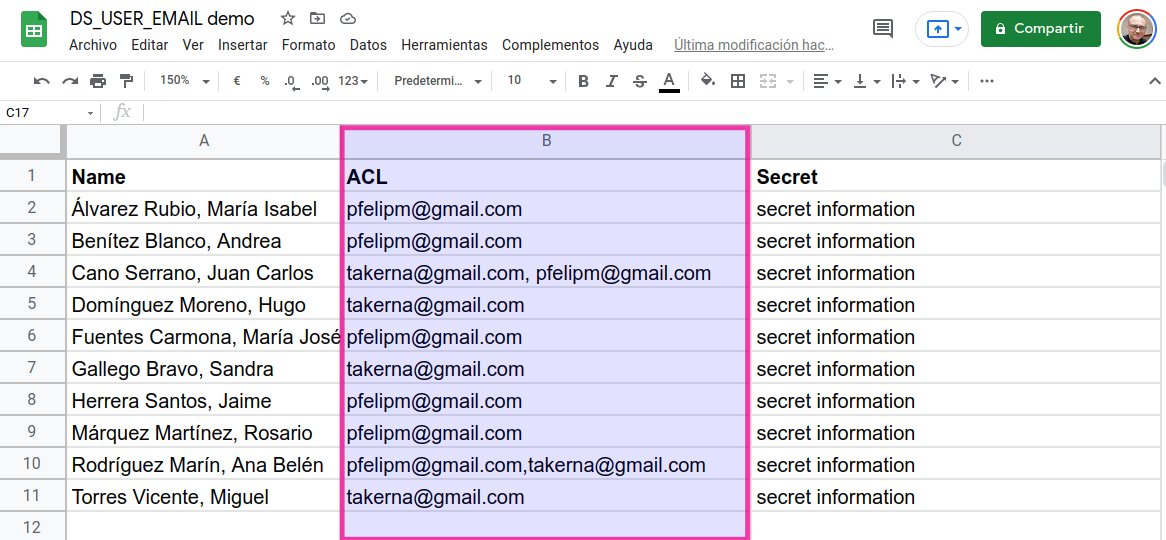
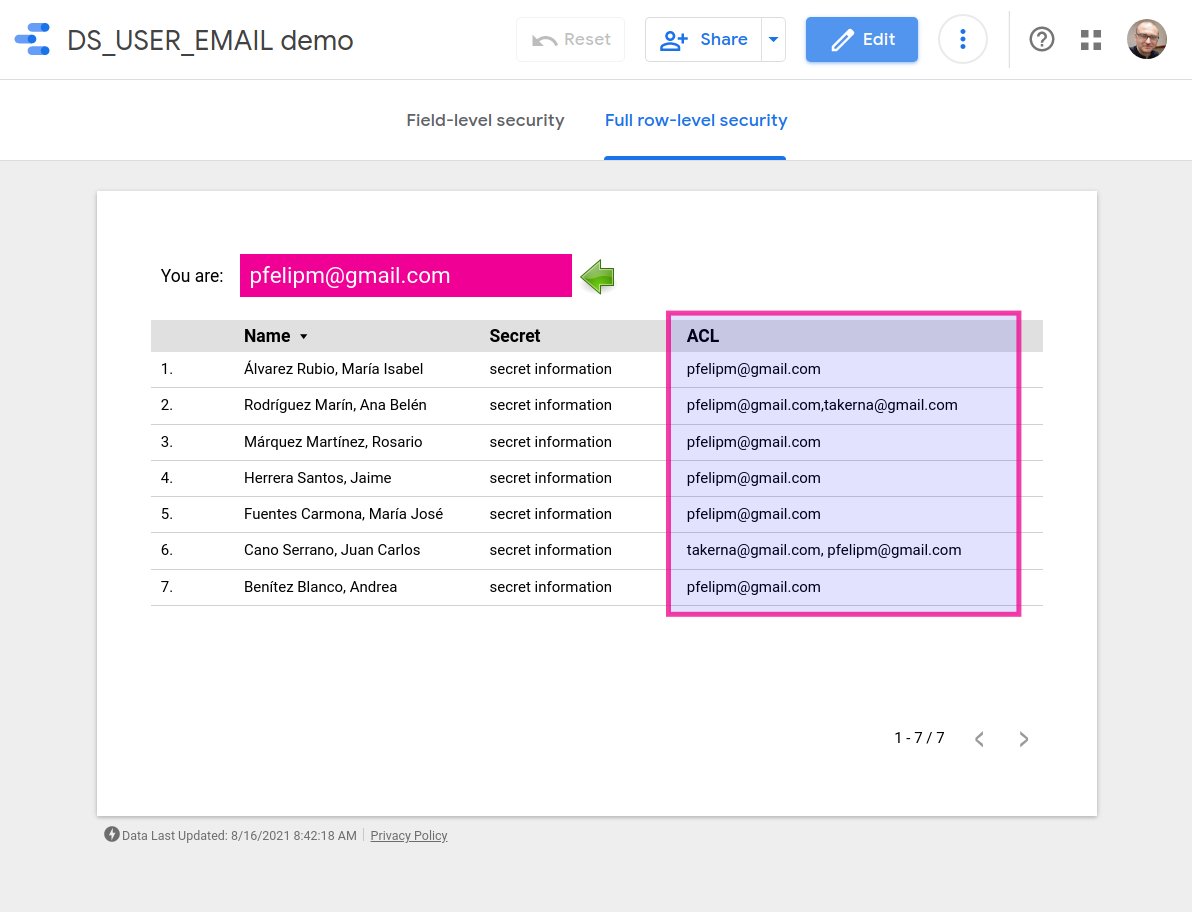
Además, puedes echarle un vistazo a este informe Data Studio, basado en el sencillo conjunto de datos que encontrarás esta hoja de cálculo. Ambos se han utilizado como prueba de concepto para desarrollar esta solución.
☝ Ten en cuenta que en este informe, puramente demostrativo, se ha simulado la función DS_USER_EMAIL() utilizando un valor predeterminado en el campo DS_email del conjunto de datos en la hoja de cálculo para facilitar las pruebas, por lo que a la hora de utilizar la fórmula presentada en una situación real debe sustituirse este último por la primera.
Comentarios finales
Poco más que añadir en esta ocasión, salvo quizás destacar el enorme desarrollo que Data Studio ha venido experimentando en los últimos años, mejoras que se han traducido no solo en la llegada constante de nuevas características sino en un incremento notable de la potencia de su lenguaje de fórmulas. Esperemos que estas mejoras nos permitan pronto utilizar expresiones calculadas en la funciones de comparación con expresiones regulares.
Desde luego, el Data Studio actual se parece más bien poco al que usábamos allá por febrero de 2017, cuando esta herramienta pasaba a ser totalmente gratuita, en mi opinión una de las razones que han propulsado su adopción en los últimos 3 o 4 años.
Como siempre, muchas gracias por leer hasta aquí. Solo recordarte que la caja de comentarios justo aquí abajo queda a tu disposición.
Uso 🍪 (a) técnicas, necesarias para el funcionamiento de esta web, (b) analíticas, para analizar el tráfico (sin registrar ningún dato personal, por lo que no se pide consentimiento) y (c) funcionales, para proporcionar características sociales (compartir y comentarios). Selecciona qué cookies deseas permitir y consulta la política de privacidad.









Comentarios